Specifically Instruction Pipelining. Pipelines are just an abstract technique.
5 Stages of a Pipeline
- IF (Instruction Fetch)
- ID/RR (Instruction Decode / Reset Register)
- EX (Execute)
- MEM (Memory Access)
- WB (Write Back)
Responsibilities of Each Stage
- IF - fetch instruction in IR and increment PC
- ID/RR - decode and read register contents
- EX - performan arithmetic/logic if needed, address computation if needed
- MEM - fetch/store memory operand if needed
- WB - write to register if needed
The opcode is passed through ALL buffers because it encodes what the appropriate datapath actions are for next stage
It is stored at the beginning of ALL buffers

| Buffer | Who’s Output? | Contents |
|---|---|---|
| FBUF | IF | Essentially contains the IR |
| DBUF | ID/RR | Decoded IR and values read from register file |
| EBUF | EX | Primarily contains result of ALU operation plus other parts of the instruction depending on the instruction specifics |
| MBUF | MEM | Same as EBUF if instruction is not LW or SW; If instruction is LW, then buffer contains the contents of memory location read |
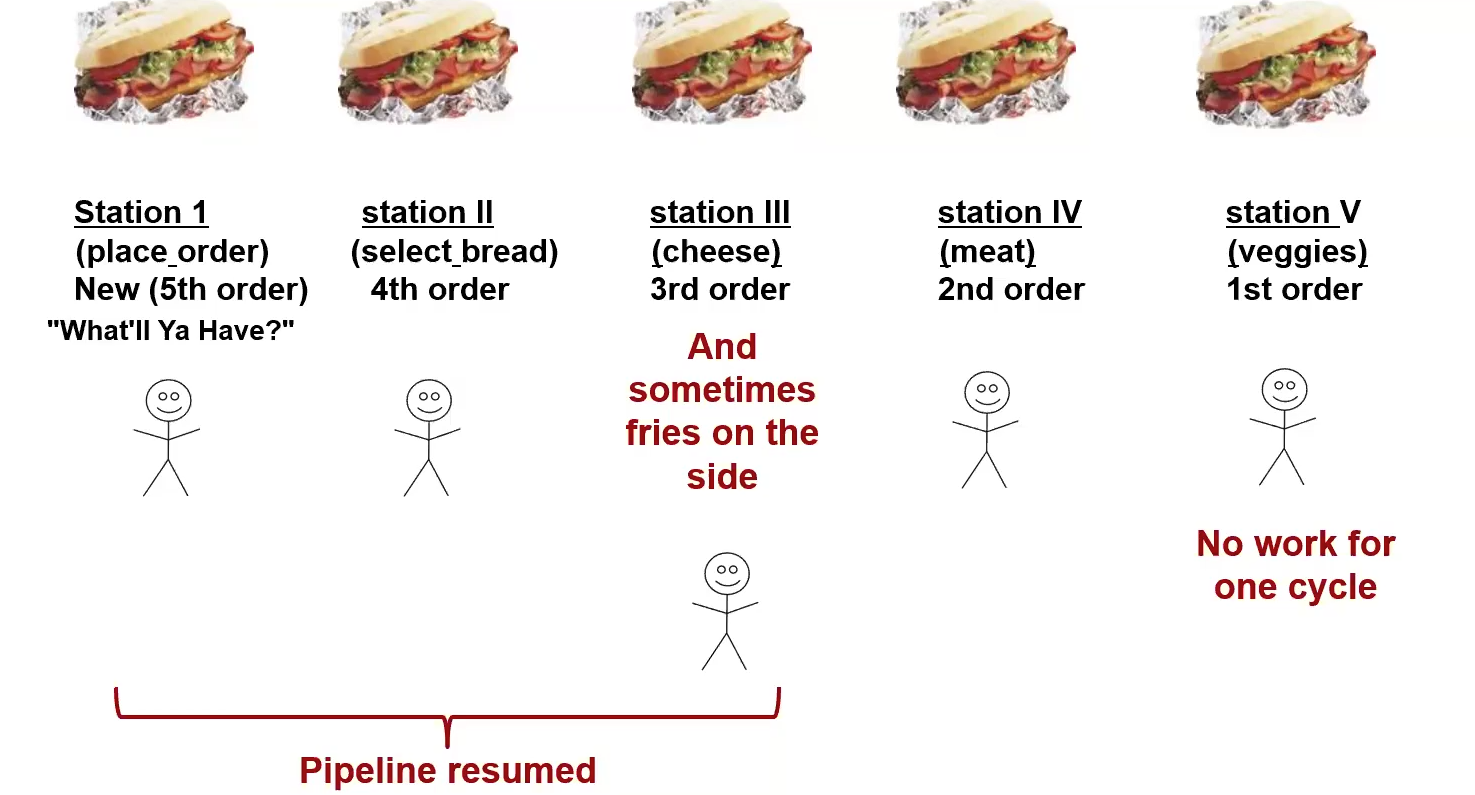
Bill’s Sandwich Shop Analogy
The figure is an analogy for a pipeline. As opposed to one worker making all sandwiches, tasks are delegated as one task per employee. Each employee hands off their current sandwich down the line, along with an order form. In this organization, all stations will fill up, and there will be one sandwich per cycle instead of per 5 cycles. Another analogy for what this is like is a hose. You turn on the faucet and after a brief while, you get a continous stream of water.
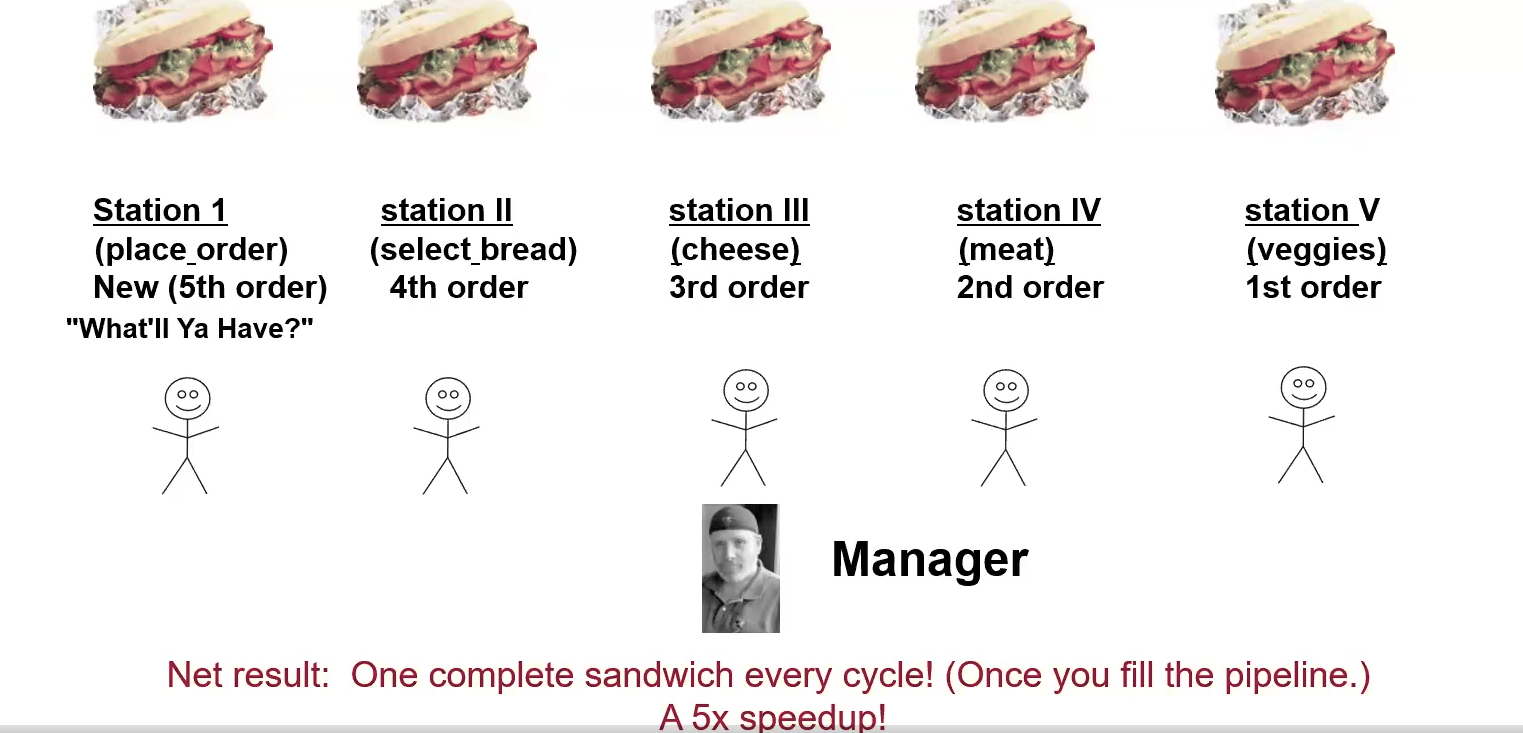
- Some stages don’t do anything for some orders
- Each stage works on a different instruction, in parallel
- Each stage passes two things to the next
- The order form
- This is equivalent to the IR
- A partially assembled sandwich
- This is equivalent to intermediate results
- The order form
- Unequal division of labor causes backups
Accordingly, you can imagine how you could implement this pipelining for the macrostates.
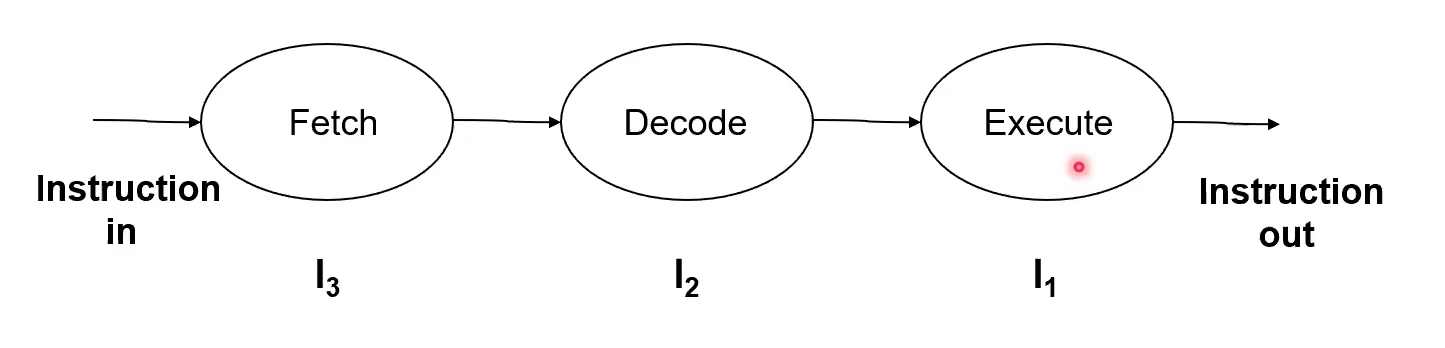
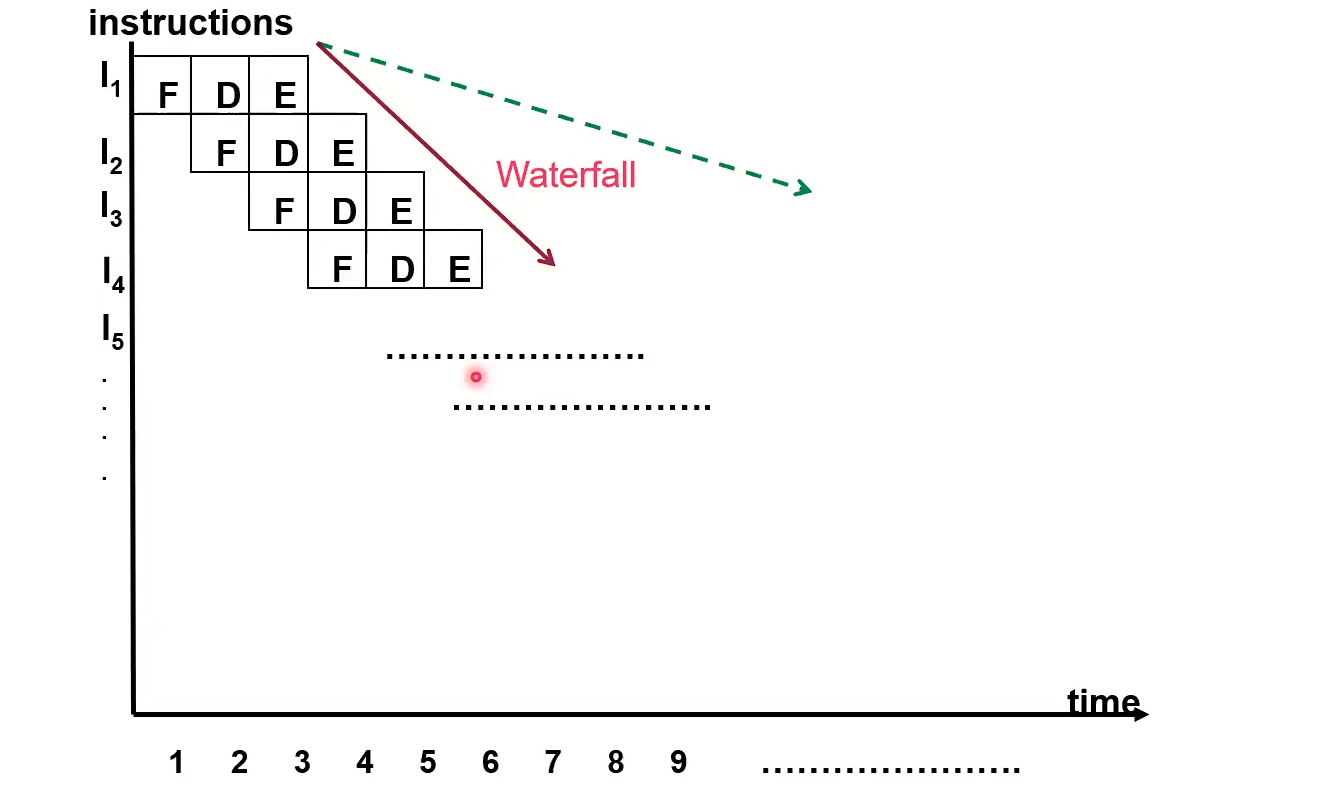
And this is how it would actually work.

IF - fetch instruction in IR and increment PC
ID/RR - decode and read register contents
EX - performan arithmetic/logic if needed, address computation if needed
MEM - fetch/store memory operand if needed
WB - write to register if needed
Each stage is separated by registers, which are called “buffers” in this context, because they buffer between stages
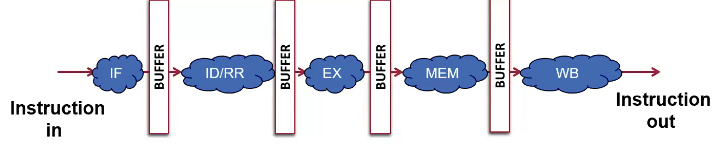
| Stage | Units in Use |
|---|---|
| Fetch | ALU, PC, MEM |
| ID/RR | RegF, Decode logic |
| EXEC | ALU |
| MEM | MEM |
| WB | RegF |
| Conclusion: we need a deticated datapath for each stage. | |
| ![[Pasted image 20250918230822.png | 500]] |
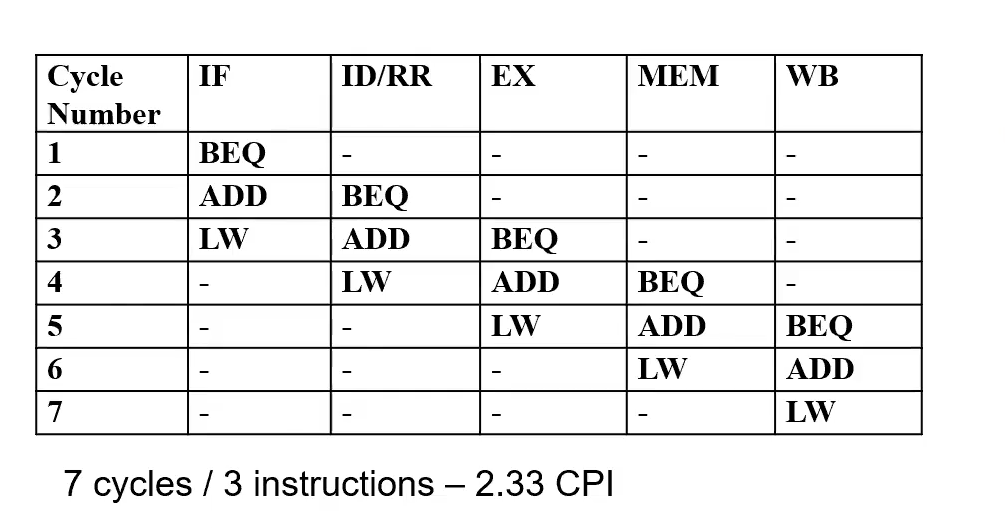
Pipeline Stall
This example is a Structual Hazard because there are not enough resources in the pipeline to avoid serialization at station III. There is partial serialization in this pipeline due to the hazard. A stall can be caused by any hazard.
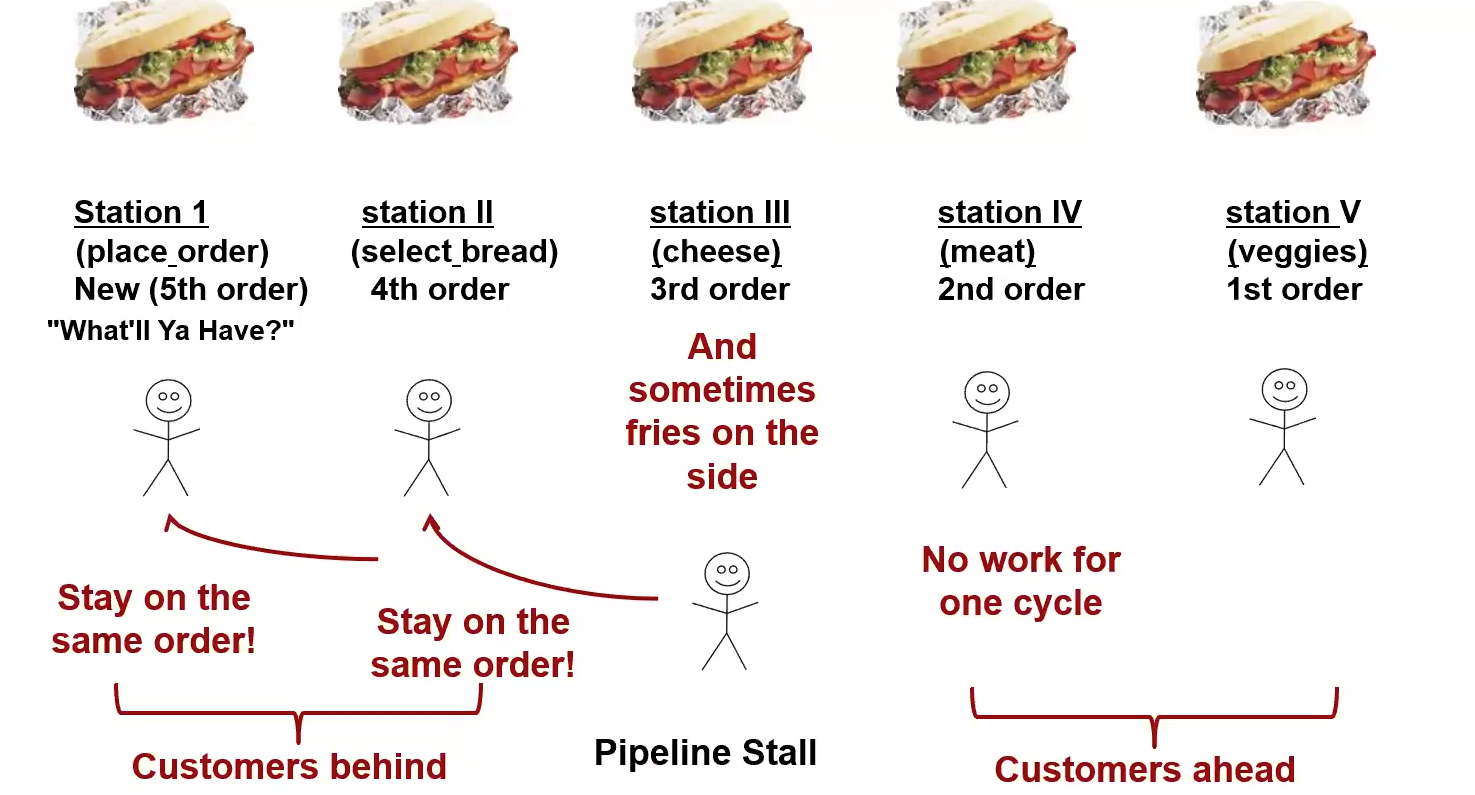
 This results in a NOOP Bubble propogating down the pipeline. You can also solve this by adding more hardware.
This results in a NOOP Bubble propogating down the pipeline. You can also solve this by adding more hardware.
Bubble
- NOOP “Bubbles” propogate through the buffers of pipeline stages downstream of the one taking more than more cycle, during a Pipeline Stall.
- A Compiler will try to optimize the order of expressions to minimize bubbles in the pipeline
Hazard
- Hazards result in serialization, aka slowing down
- The longer the pipeline, the larger the potential maximum hazard slowdown
Structual Hazard
Structual hazards are caused by hardware limitations. For example, if BEQ branches, we have to use the ALU twice! If we only have one ALU in the datapath for EX, then all the insructions behind the BEQ in the pipeline have to wait for it, as it cycles twice in EX.
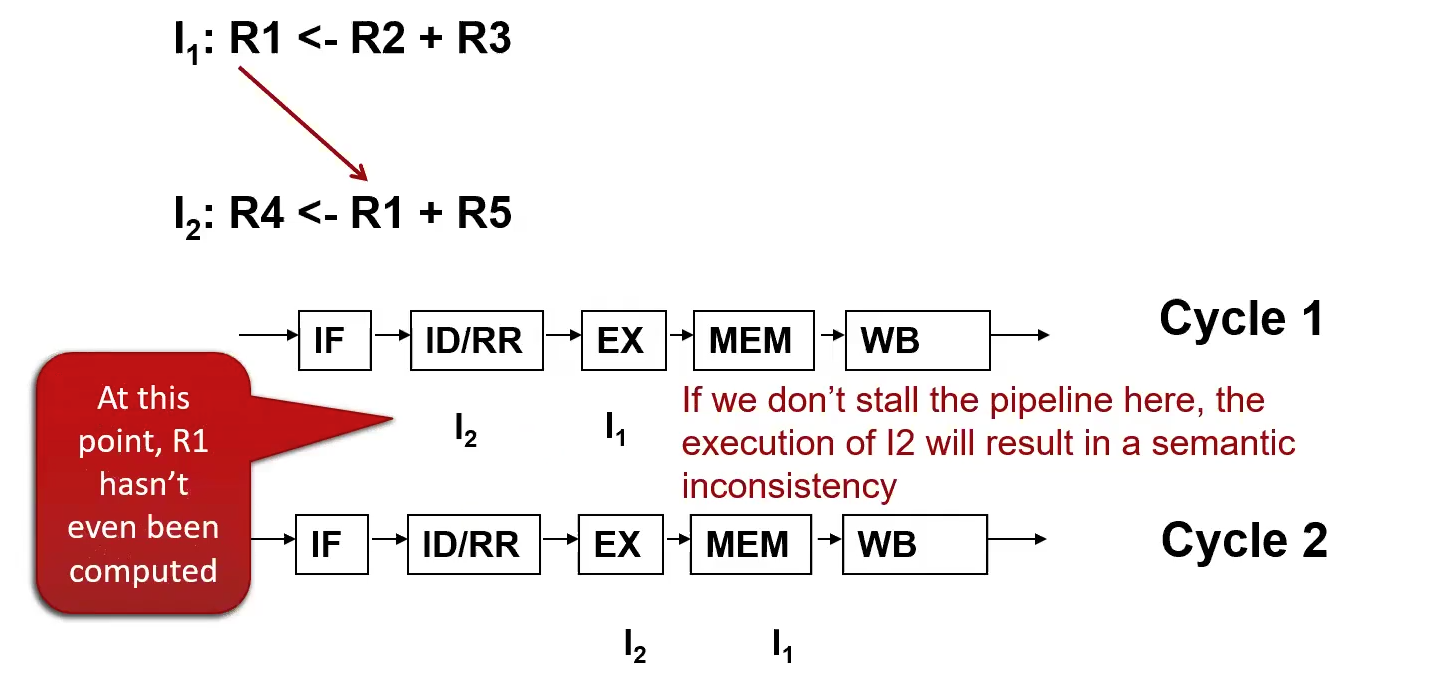
Data Hazard
When pipelining destroys the serial semantics of a program.
- Program limitations, mismatch between pipelining and serial external appearance of program
- When pipelined (i.e. out of serial order) execution leads to semantic violations. The next instruction may clobber the information needed for intermediate calculations of the current instruction.
Read After Write
(RAW)
True dependency
Write after Read
(WAR)
Antidependency
Write after Write
(WAW)
Output dependency
Control Hazard
Changes to the control flow of a process, e.g. branching.
“Branches cause disruption to the normal flow of control and are detrimental to pipelined processor performance”
Busy Bit
- Each Register in the Register File gets a bit called the “Busy Bit”.
- A register’s busy bit is set when it is not yet ready to be accessed.
- Any instruction that is not yet executing whose registers have a least one busy bit must wait for the currently executing instruction to finish before proceeding down the pipeline.
- ID/RR sets the busy bit, WB resets it
Register Forwarding
- RP (read-pending) signal associated with each register to indicate an instruction is stalled in ID/RR for this register value
- if RP { use forwarded value } else { read entry from DPRF }
- The forwarded value is passed back from the deeper, associated instruction to the one in ID/RR if applicable
- Eliminates all Bubbles caused by Read After Write hazards for all instructions that get their result in EXEC
- for LW, you have to wait for it to get its result from MEM, so you get an EXEC bubble
- Faster than Busy Bit because you avoid stalling, but more complicated
Pipelined Branching
Conservative
Conservative is the same as stalling the pipeline
- Wait until branch outcome is known.
- Stall the pipeline, send NOOPs from IF state
- Resume normal execution when branch outcome is known
- e.g. Result of comparison A-B is known
- IF there is need to branchh, PC gets the target address of the branch and IF stage is flushed
- Two Cases
- Branch TAKEN
- Branch NOT TAKEN
Branch Prediction
(Modern Technique) Assume branch not taken Continue in pipeline Prediction may be wrong, flush the instructions at IF and ID/RR, adjust PC if needed The term for this is speculative execution If prediction is correct, then we get pipelining benefit, and it is as if no branch took place
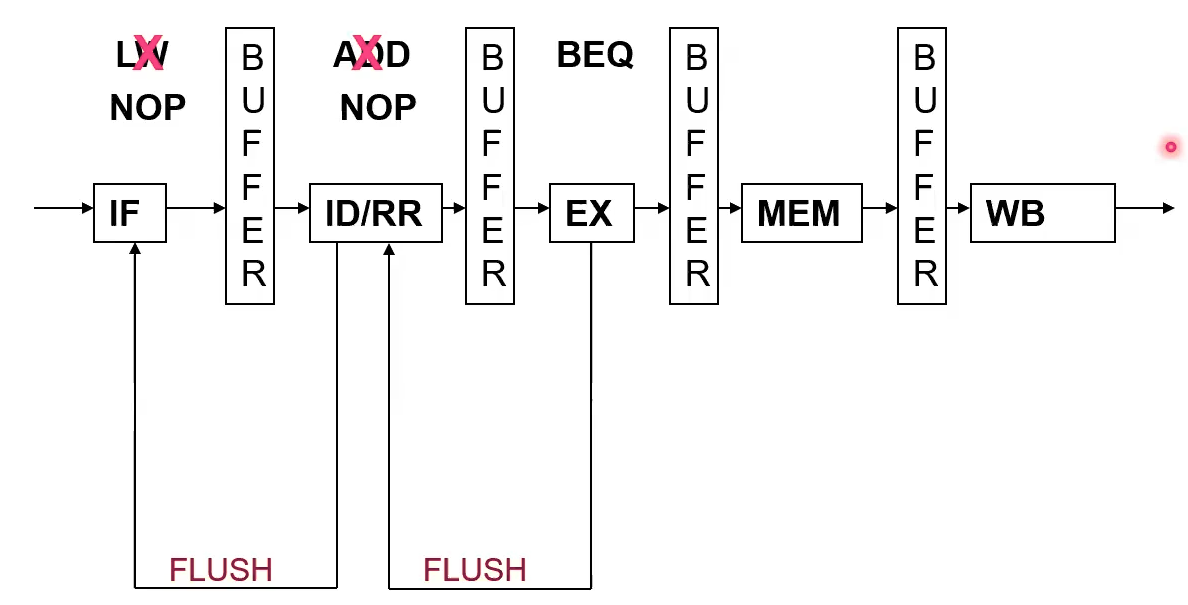
It is impossible to always guess whether we branch. See Halting Problem.
Branch Target Buffer
Stores address of branch, outcome, and target address for each branch, during the process of Branch Prediction
Link to originalHeuristics
- Compare target with current PC
- Loops generally branch backwards (target < PC)
- Guess branch will be taken
- Conditionals generally branch forward (target > PC)
- Guess branch won’t be taken
- Some ISAs have 2 different families of branch instructions so that the Compiler can signal whether it thinks the branch will be taken or not
- Keep a history of branch target addresses, e.g. Branch Target Buffer where there are 3 columns of PC of branch instruction, Taken?, PC of branch target address
- “If we took it last time, we will probably take it this time”
Delaying Branch
(Not super important)
Link to original
- Ignore the problem in hardware (i.e. don’t automatically generate NOOPs in fetch stage)
- Give the NOOP instructions to the compiler
- e.g. the instruction after a branch is always executed
- Let the compiler worry about it
- Compile in a NOOP instruction after every branch instruction
- Therefore the compile has the abillity to optimize the branching itself, e.g. by choosing whether or not the semantics of the program change when a NOOP is removed. If not, then they can be removed
Discontinuities
See Discontinuities. An interrupt can occur at any time. Any one of the instructions in the pipeline can cause a discontinuity.
- When do we take the interrupt?
- We could stop, drain the pipeline, then go to the interrupt state
- Slow
- Look for external INT in a specific stage (e.g. EX state)
- DRAIN preceding stages
- FLUSH subsequent instructions
- We could stop, drain the pipeline, then go to the interrupt state
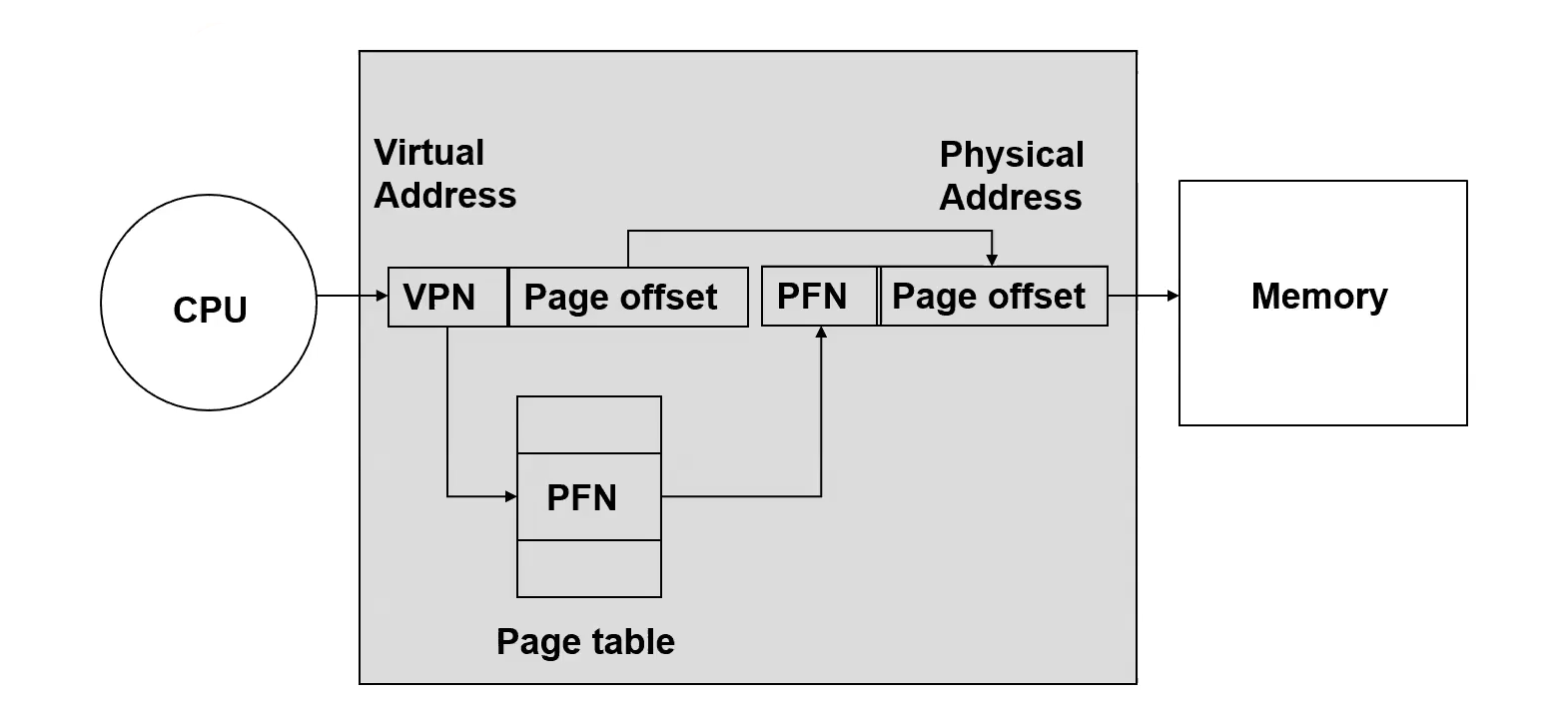
Virtual Memory
A pipelined processor with Virtual Memory will experience major inefficiencies in its naive implementation; Every memory access requires two memory accesses: accessing the page table entry, followed by the actual memory word. This is awful for our pipeline because all memory accesses introduce bubbles. Additionally, there is one bubble for every instruction because we have to access page table entries in our fetch stage.
The entire page table is not going to fit in registers. And even if they did, we would have to reload all of them every Context Switch However, we definitely can fit a subset of those entries in registers. Putting some entries in a subset register file actually works well due to Locality.Broker
Link to original
Locality
If we are running instruction
it is very likely that the next instruction is which in the same page or an adjacent page
- Sequential Instructions
- Contiguous Data Structures
Spatial Locality
Refers to the high probability of a program accessing adjacent memory locations
Temporal Locality
Refers to the high probability of a program repeatedly accessing the same memory location that it is accessing currently
Link to original
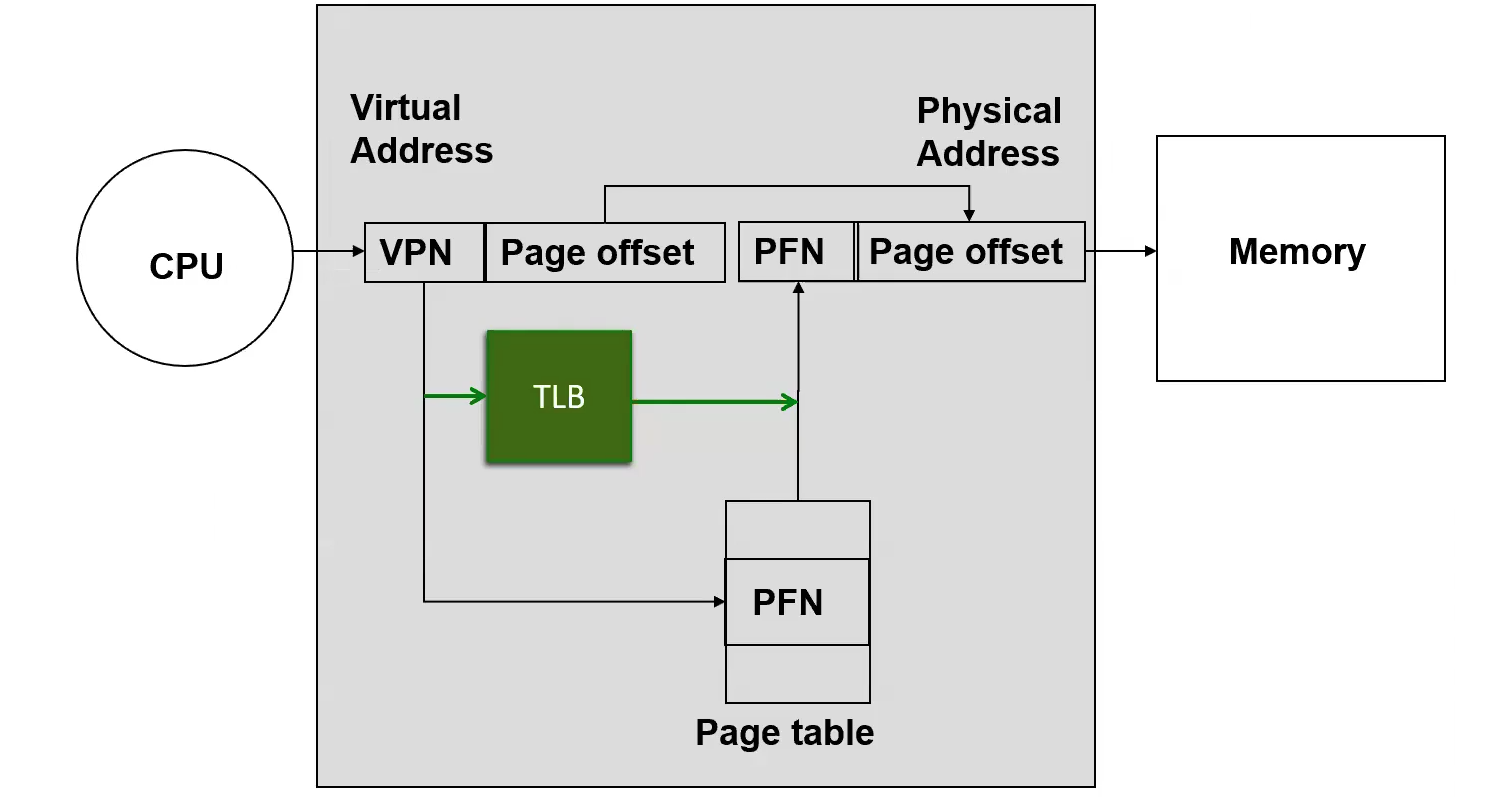
Use a Translation Lookaside Buffer for this subset of the Page Table
Usage
Use a TLB to reduce bubbles. If the TLB hits, we have a fast path and no bubbles.
Link to original
- TLB can only hit if
- Entry exists
- Process has access (user proc can’t use kernel entry)
- Entry is valid If the TLB misses, we have a slow path, bubbles, and the TLB is updated. The point of a TLB is anticipating Locality in Programs; if a program has poor Locality, then we have poor performance, because the TLB will constantly miss, and we will degenerate into the performance of the naive approach.
Pipeline with Caches
Instructions and data have separate caches.
