Ephermeral holding of data for the purpose of expediting future accesses. In this entry, the cache exists as hardware. For more algorithmic notions of caching, look at Memoization.
When a CPU needs to access a physical address, the access to main memory is preceeded by an access to some cache. If there is a cache hit (the memory address and its contents are cached), then we save time by not needing to perform a slow memory access
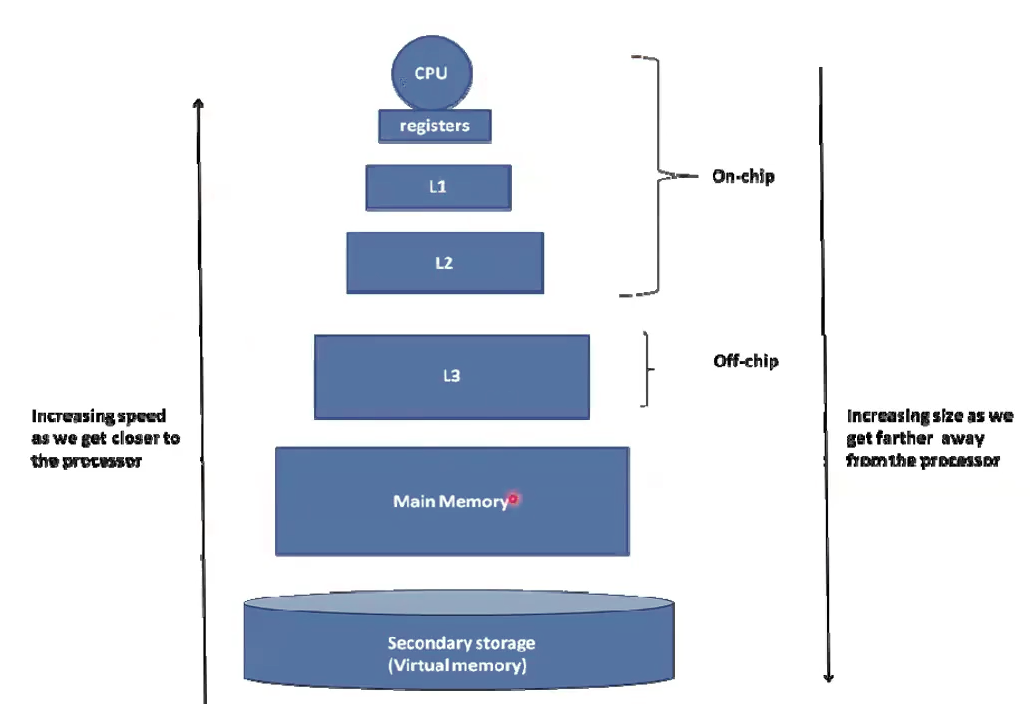
Typical memory organization, including CPU caches.
Increasing speed as we get closer to CPU, but with smaller capacity.
The Virtual Memory mention on secondary storage is referring to the Swap Space part of Virtual Memory Management
Locality
If we are running instruction
it is very likely that the next instruction is which in the same page or an adjacent page
- Sequential Instructions
- Contiguous Data Structures
Spatial Locality
Refers to the high probability of a program accessing adjacent memory locations
Temporal Locality
Refers to the high probability of a program repeatedly accessing the same memory location that it is accessing currently
Link to original
Working Set
Which addresses show up in the cache when a Process runs?
Context Switch
We do nothing. This is because we’re using Physical Addresses, unlike the TLB
Flushing
The cache must be flushed upon OS bringing in Page from disk and bypassing the cache, because if I/O bypasses the cache, any cache entries reference the I/O buffer will be invalid.
Physically Indexed Physically Tagged Cache
The normal way 🙂 Requires TLB lookup, followed by cache access: 2 accesses
Virtually Indexed Physically Tagged Cache
Cache & TLB accessed in parallel: 1 access (2 in parallel)
If you make the page offset the same bitsize as the index + block offset size, then you can start the cache read without waiting for the TLB.
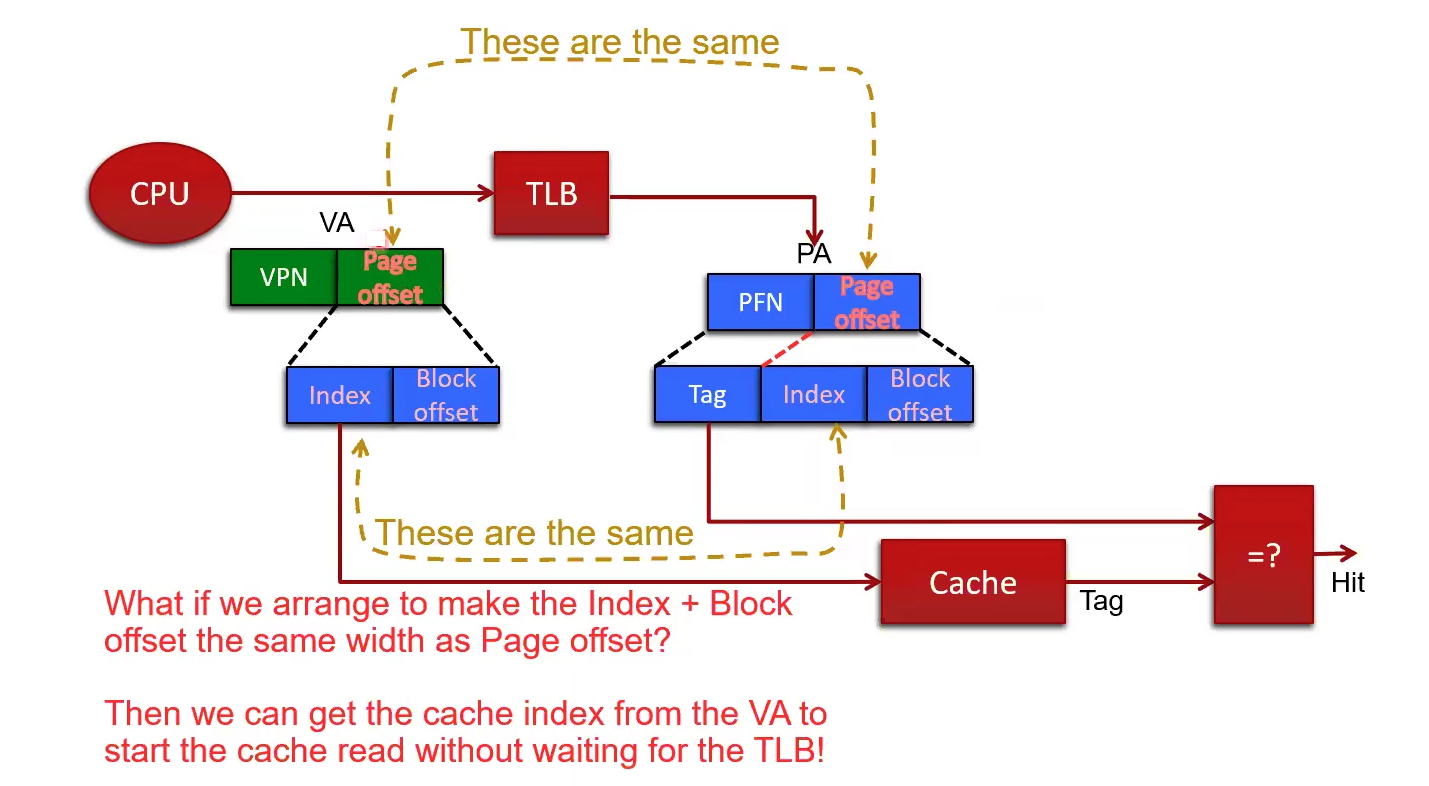 The tradeoff is that the index determines the max size of the cache, limiting the size of the cache.
The tradeoff is that the index determines the max size of the cache, limiting the size of the cache.
Metadata
Anything in a cache entry that is not the value at the memory address.
Overhead
LRU
For
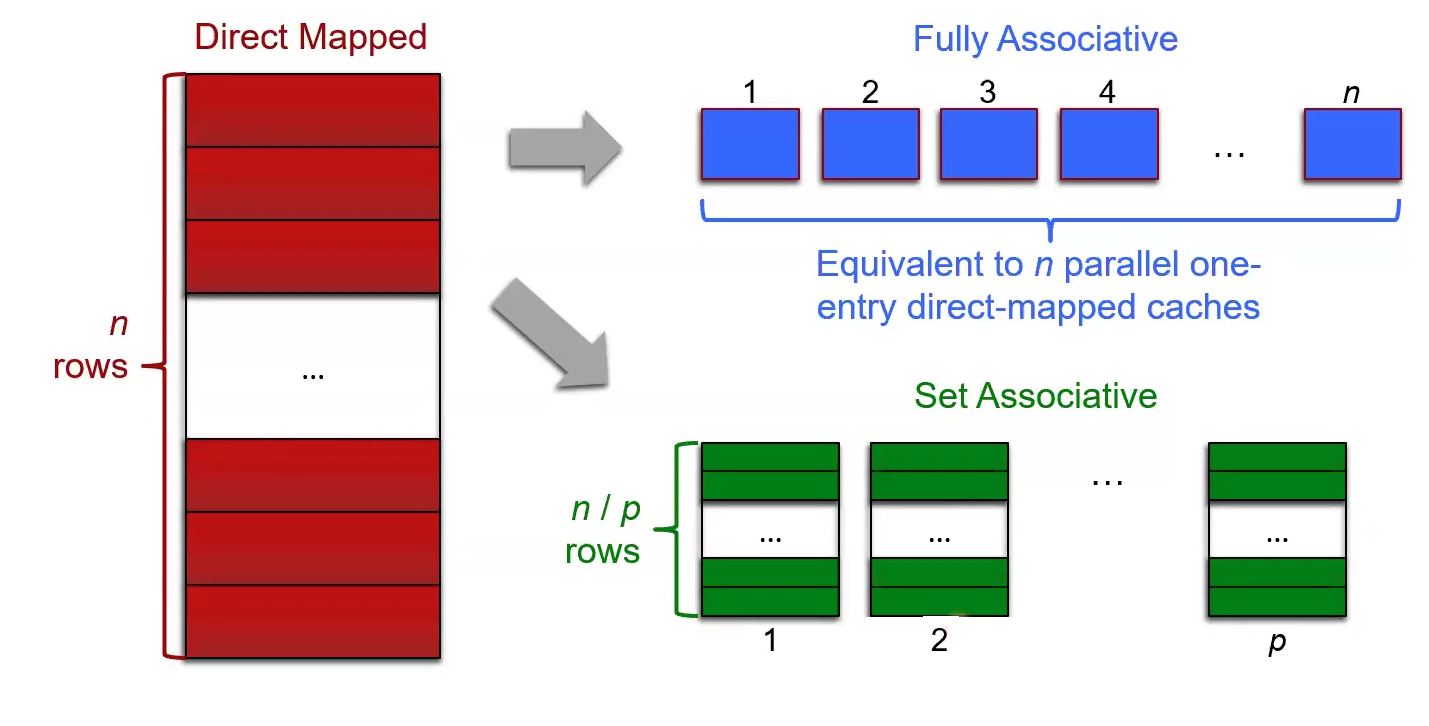
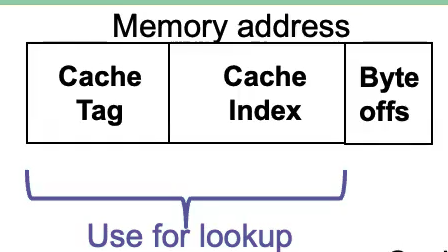
Cache Organization
Cache… line = block = entry = element = one unit of cached data stored in the cache
- Cache Set: a “row” in the cache. The number of blocks per set is determined by the type of set.
- DMC: n sets, 1 entry
- P-way set associative: n/p sets, p entries
- Fully associative: 1 set, n entries
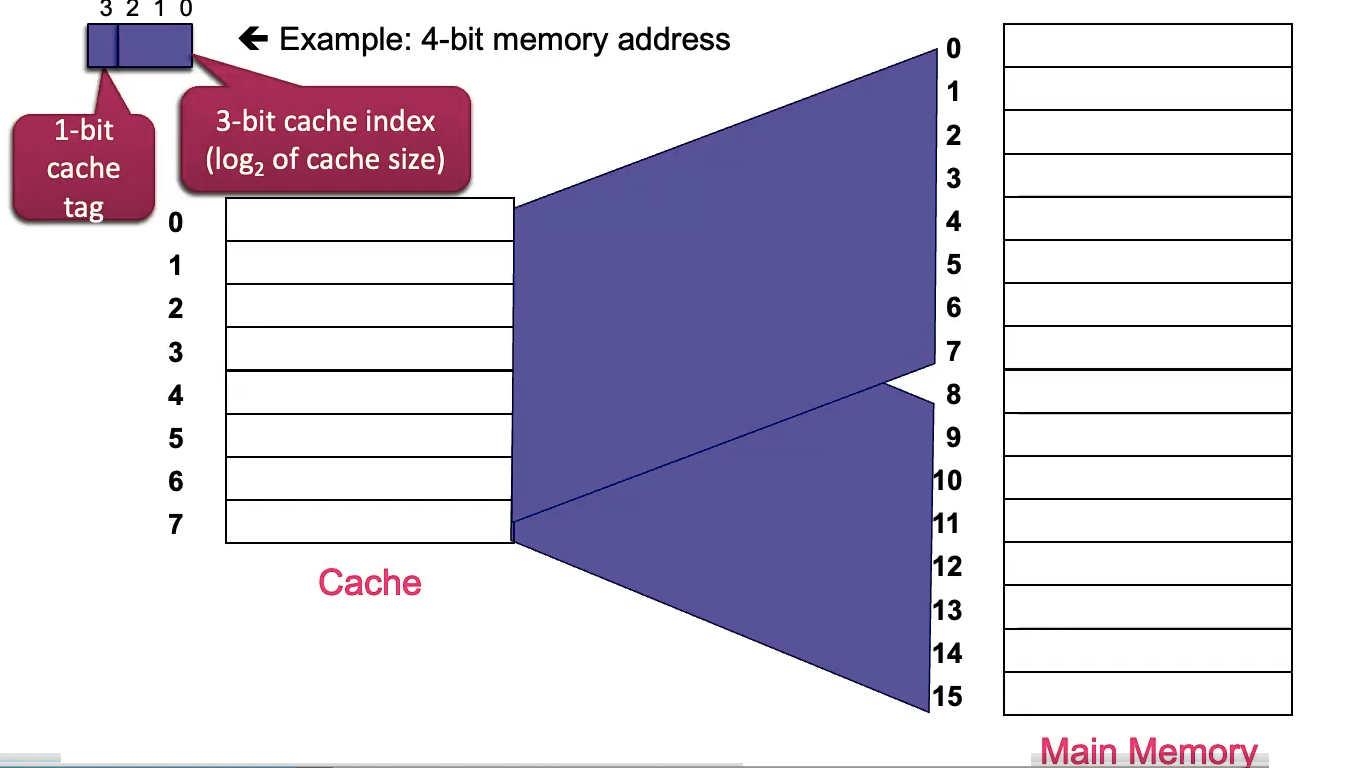
Direct Mapped Cache
- Any potential memory block only has one valid location in the cache. Least hardware complexity. Least flexible.
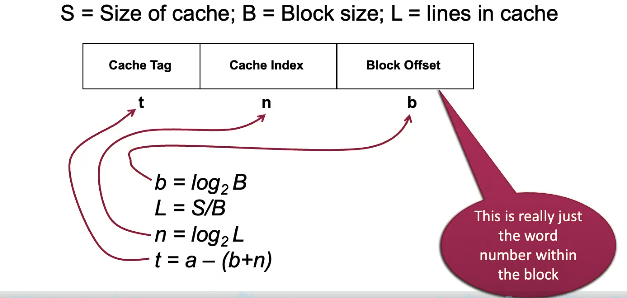
- For a
size cache, the index into the cache is the last bits of the memory address. Hence, this kind of cache is called a direct cache, because you just perform modulus base cachesize to map the memory space into the cache space. - We use the last
bits, because if we use the first bits, we will wreck our spatial locality
- We use the last
- The tag is remaining part of the memory address that isn’t being used for the cache index. We use the tag to label and disambiguate the data in the cache.
- The Valid Bit indicates is the given entry is filled or garbage

- Benefits from both Spatial Locality and Temporal Locality
- Can cause inefficienct use of cache with overlapping Working Sets
- There is an optimal zone for the size of the cache blocks, striking the balances between exploiting Spatial Locality and memory transfer of updating the working set becoming a bottleneck
In a realistic memory system, the size of a word, and the precision of addressability might not be the same. In this case, you would just some of the last bits, where those bits encode addresses in the same memory word.
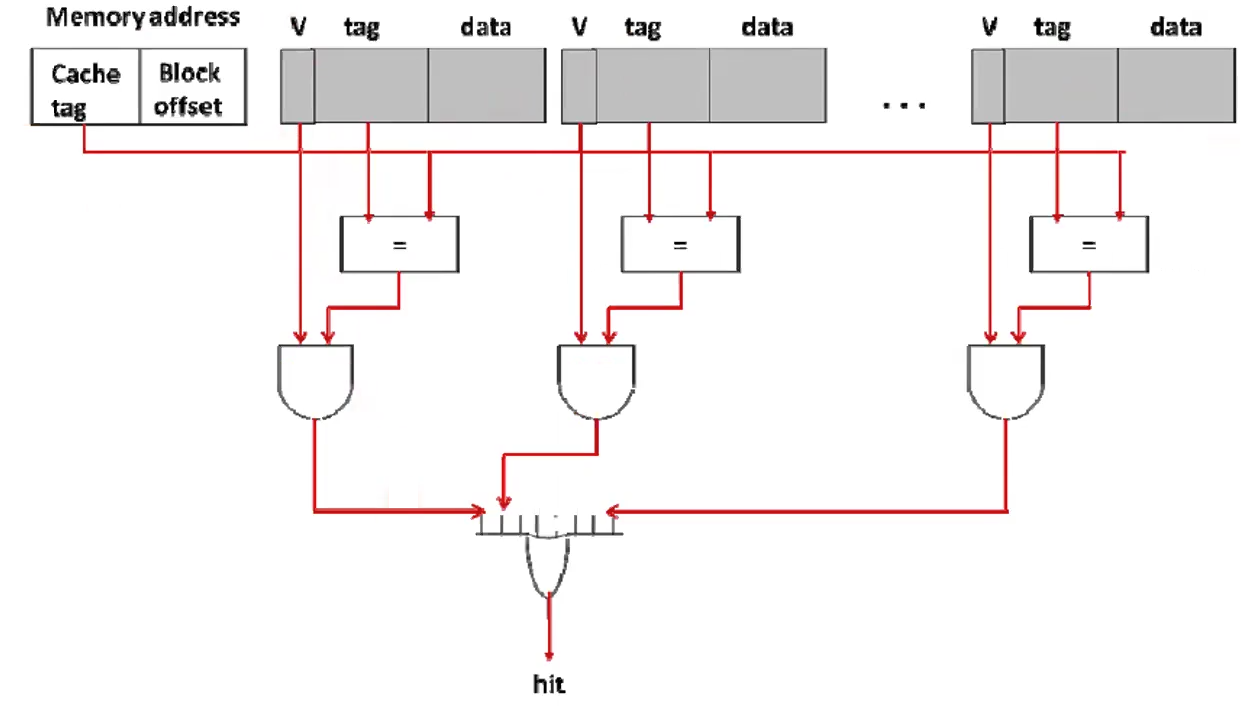
Fully Associative Cache
Any memory block can be place in any cache line. Most flexible.
Because a block can go anywhere, the cache uses a Replacement Algorithm to decide where the block should go
There is no notion of tag and index; the entire thing is a tag. This is because any address. There is still a block offset like the other organizations.
 Requires more hardware complexity because it needs a word-sized comparator for every cache entry
Requires more hardware complexity because it needs a word-sized comparator for every cache entry
Hit/Miss determined with a comparator per cache entry that inspects the tag. It also requires the entry to be valid.
Set Associative Cache
Compromise between DMC and FAC. DMC and FAC are really just degenerate cases of SAC. DMC is 1-way SAC. FAC is N-way SAC.
4-way SAC. Really just 4 DMCs connected together.
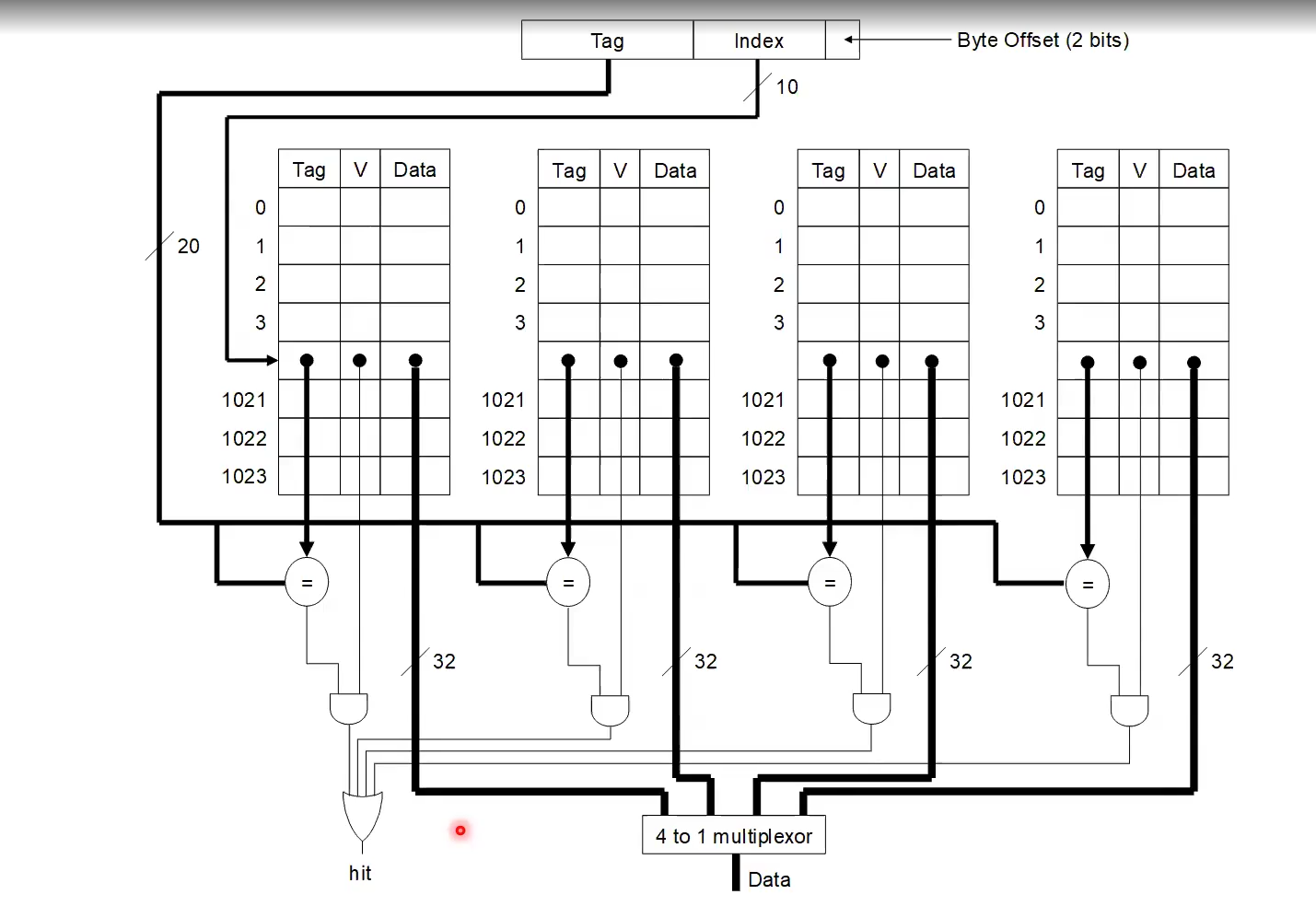 2-Way SAC only needs one bit per entry for LRU.
For N-way SAC you need
2-Way SAC only needs one bit per entry for LRU.
For N-way SAC you need
Misses
Super Important Nuance!
Check in this order: Compulsory > Capacity > Conflict That is to say, if a word is being access for the first time, it will always be a compulsory miss, even if you happen to also be evicting an entry like in a conflict miss.
Compulsory Miss
aka “Cold Miss” The first time you access a word, you are guaranteed to have a cache miss, because that word cannot be in the cache yet.
Capacity Miss
The cache is completely full, and the word we want isn’t in the cache.
Conflict Miss
We have to evict an entry from the cache even though the cache is not full, and it is not the first time we are accessing this word.
- E.g.
cache_index = address % cache_capacity→ all multiples of capacity will conflict - Conflict misses are misses that would not occur if the cache were fully associative with LRU replacement. Fully associative caches can’t have conflict misses, by definition.
Effective Memory Access Time
todo clean up this section
Hit rate
Effective Memory Access Time (EMAT) = 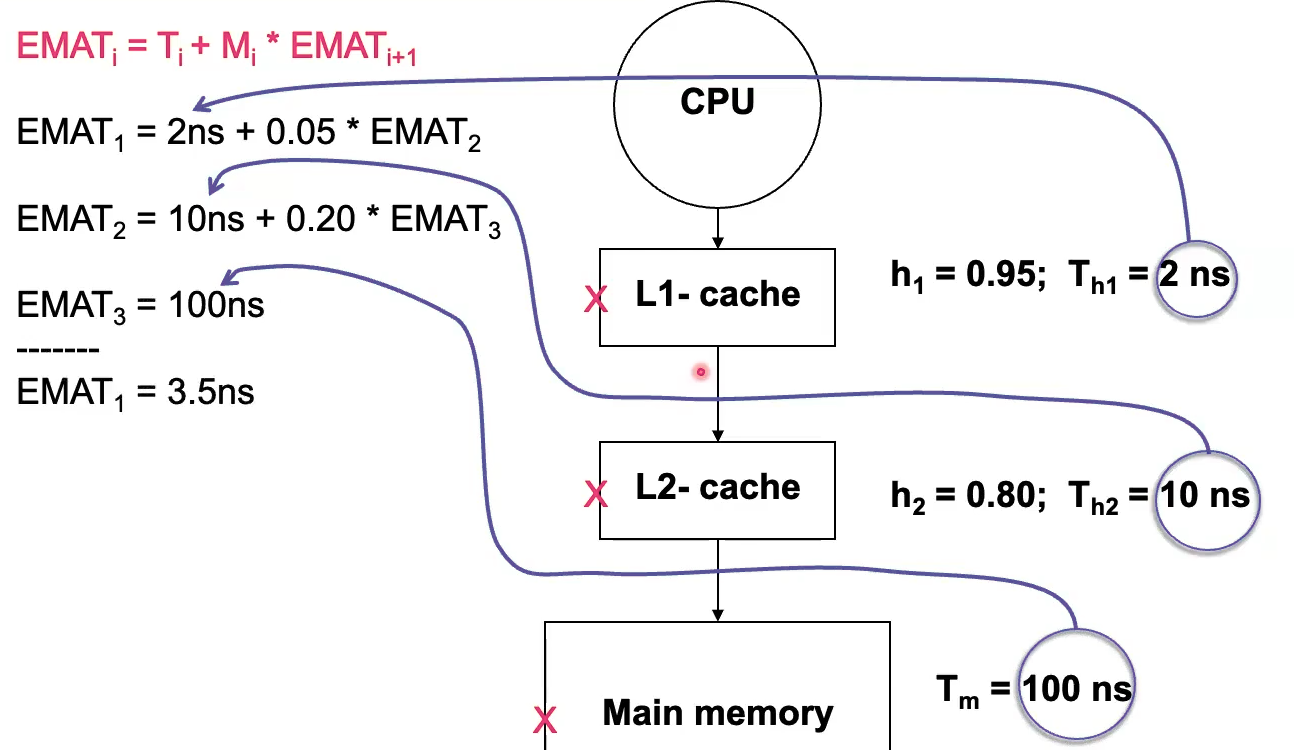
Memory Access Scenarios
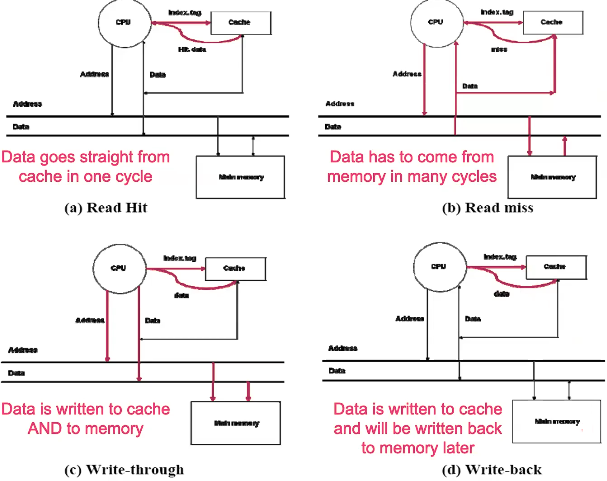
Read Scenarios
- Read Hit
- The CPU requests data from memory, but the cache already has it, so the CPU can get that memory immediately
- This is the fastest scenario
- The CPU requests data from memory, but the cache already has it, so the CPU can get that memory immediately
- Read Miss
- The CPU requests data from memory, and the cache doesn’t have it so it must be fetched from main memory and written to the cache
Write Policies
- Write Through
- A write policy where the CPU simultaneously writes to the cache and main memory
- This ensures that there is no desync between main memory and caches, which is super important for shared memory between multiple CPUs
- A write policy where the CPU simultaneously writes to the cache and main memory
- Write Back
- A write policy where the CPU initially only writes to the cache, and the main memory is updated later
Cache Optimization
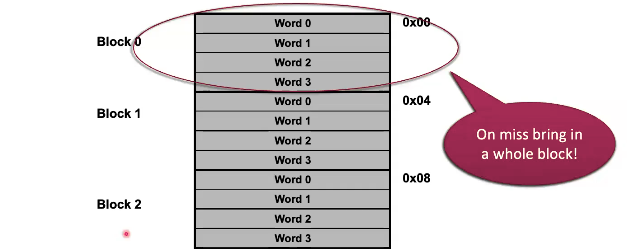
Exploiting Spatial Locality
Pipeline with Caches
Instructions and data have separate caches.
Link to original
