Using multiple threads for one Process
 Each thread requires its own stack.
Each thread requires its own stack.
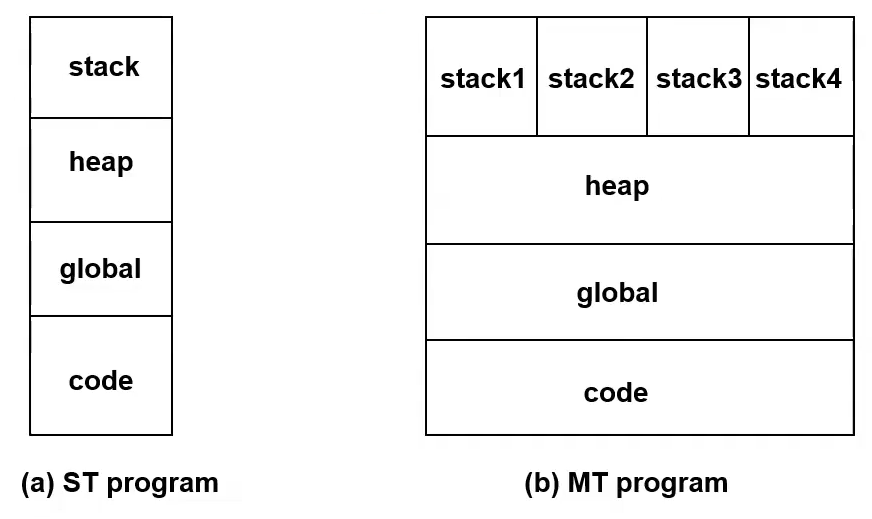 Page Table, TLB, and Cache usage all works the same under multithreading.
Page Table, TLB, and Cache usage all works the same under multithreading.
Thread Synchronization
Synchronization is the war against Race Conditions Handled by Mutexes and Condition Variables.
Mutex implementation with Atomic Read-Modify-Write Instruction. Thread-safe.
int mutex(int * lock) {
int X;
X = test_and_set(lock);
return X;
}
lock {
while (test_and_set(&mem_lock)) block the thread
}
unlock { mem_lock = 0 }
Naive Approach (Not Thread-safe)
lock { while (mem_lock != 0) block the thread mem_lock = 1 } unlock { mem_lock = 0 }However, we have to be careful about the implementation of our Mutexes, in order to guarantee synchronization. What if our mutexes have a race conditions? Imagine an Interrupt occurs in the middle of our mutex logic, and we Context Switch to another Process. Fuck.
This breaks the logical behavior of our mutexes, because they aren’t Atomic. This is essentially a Critical Section, but we can’t guard it with mutexes, because we are implementing Mutexes as the OS. This issue could lead to multiple mutexes simulataneously acquiring the same lock. NOT GOOD!
The classic solution when we have an issue where something needs to be atomic, is to add an Instruction to the ISA, and have Hardware make that instruction atomic for us! Just like RETI.
(FYI ARM and MIPS use 2 instructions one that allows only the next instruction to touch a particular memory location (Load Linked), and the second instruction that touches that memory location (Store Conditional), but having an atomic instruction is the easiest way).
Atomic Read-Modify-Write Instruction
TEST-AND-SET
TEST-AND-SET <mem-location>
- Load current value in <mem-location>
- Store 1 in <mem-location>
This allows us to:
- Test the lock and set it to 1
- If the lock tested originally as 0, we acquired it
- Else, we did not acquire it
Thread Synchronization
Bypass the Cache for TEST-AND-SET, because the caches will be wrong due to the atomicity of the test-and-set instruction.
Link to original
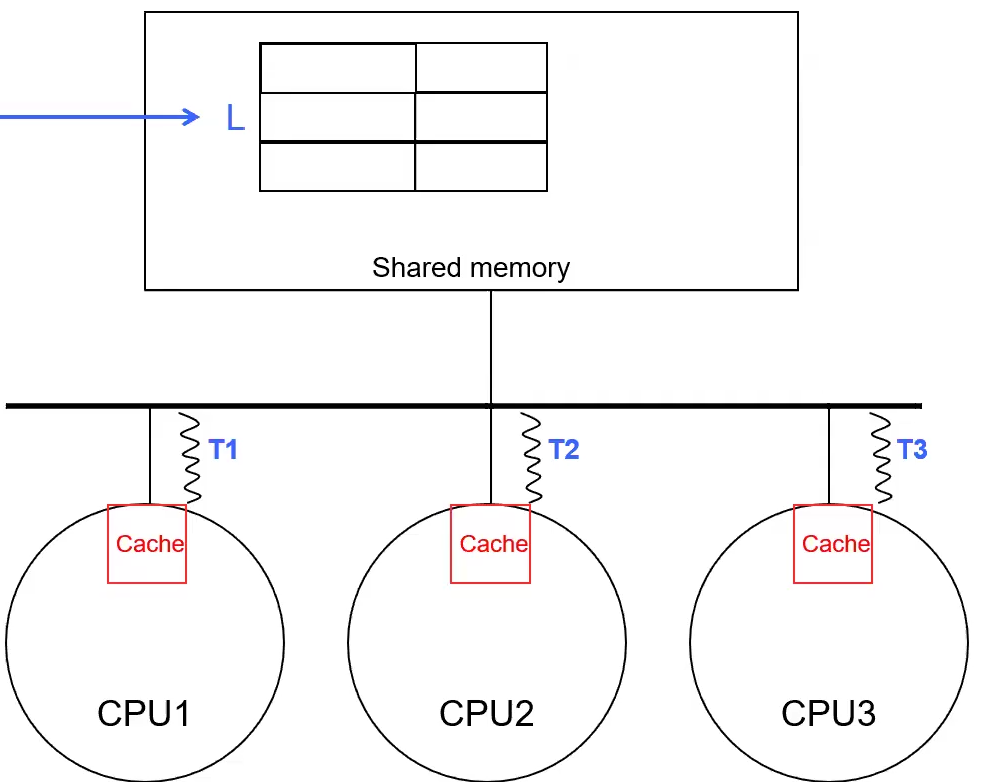
This is like COMPARE-AND-SWAP on IBM 370, FETCH-AND-ADD on Intel x86, Load-Linked + Store Conditional on MIPS and ARM.
Thread Communication
Accomplish through software by keeping all threads in the same address space by the OS Accomplish through hardware with hardware shared memory and coherent caches
Models
Producer-Consumer Model
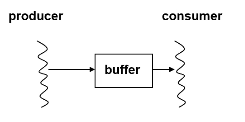 The producer-consumer problem is a multithread synchronization problem where there are two threads: the producer and the conusmer, which share a fixed size buffer that acts as a queue.
The producer’s job is to put the data it produces into the buffer.
The consumer job is to consume that data by removing it from the buffer, one datum at a time.
The producer-consumer problem is a multithread synchronization problem where there are two threads: the producer and the conusmer, which share a fixed size buffer that acts as a queue.
The producer’s job is to put the data it produces into the buffer.
The consumer job is to consume that data by removing it from the buffer, one datum at a time.
- The producer shall not add data into the buffer when it is full.
- The consumer shall not remove data from an empty buffer.
- The producer and consumer shall not access the buffer simultaneously.
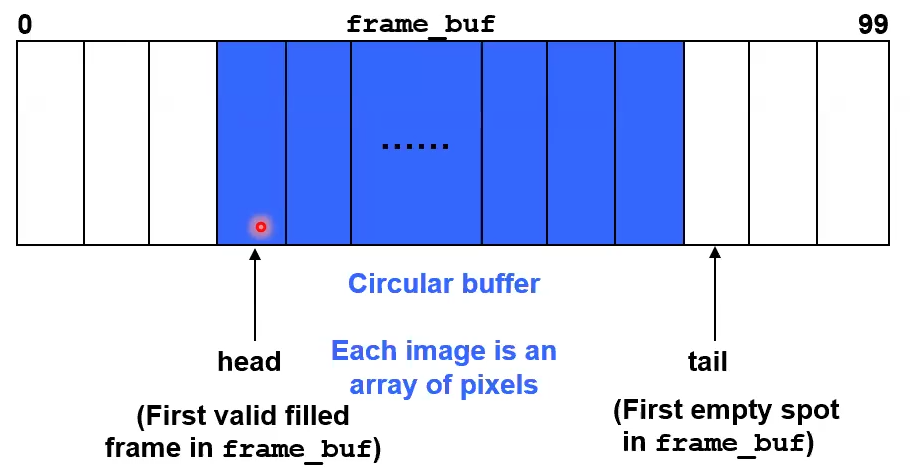
Circular Buffer
We implement this queue with a circular buffer that has a head and tail pointer.
Head points to the first filled frame in the buffer.
Tail points to the first empty spot in the buffer.
Insert elements at tail and then increment the pointer mod base size.
Remove elements at head and then increment the pointer mod base size.
Only the consumer touches head.
Only the producer touches tail.
You can track if the buffer is full or not EITHER with a current size variable, or with a buffer entry, i.e. not allowing tail to overlap with tail (check if tail is immediately before head to see if the buffer is full)
Dispatcher Model
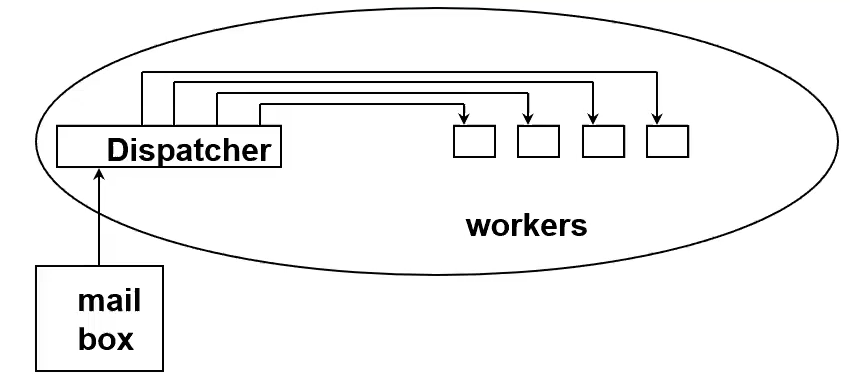
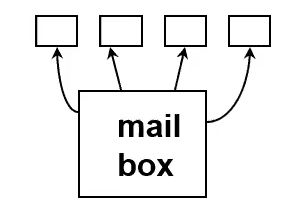
Team Model
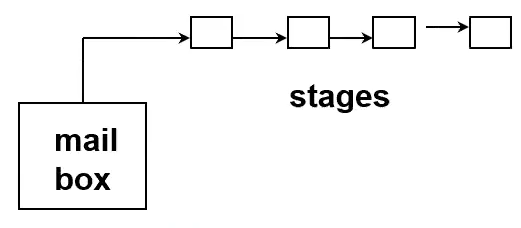
Pipelined Model
Producer-Consumer Model, but there are stages.
Implementation
Kernel-level Threads
This is the norm
- Thread switching is more expensive
- Makes sense for blocking calls by threads
- Kernel becomes more complicated dealing with process and thread scheduling
- Thread packages become OS dependent and nonportable, hence POSIX threads exist to provide a standard
Two-level OS Scheduler
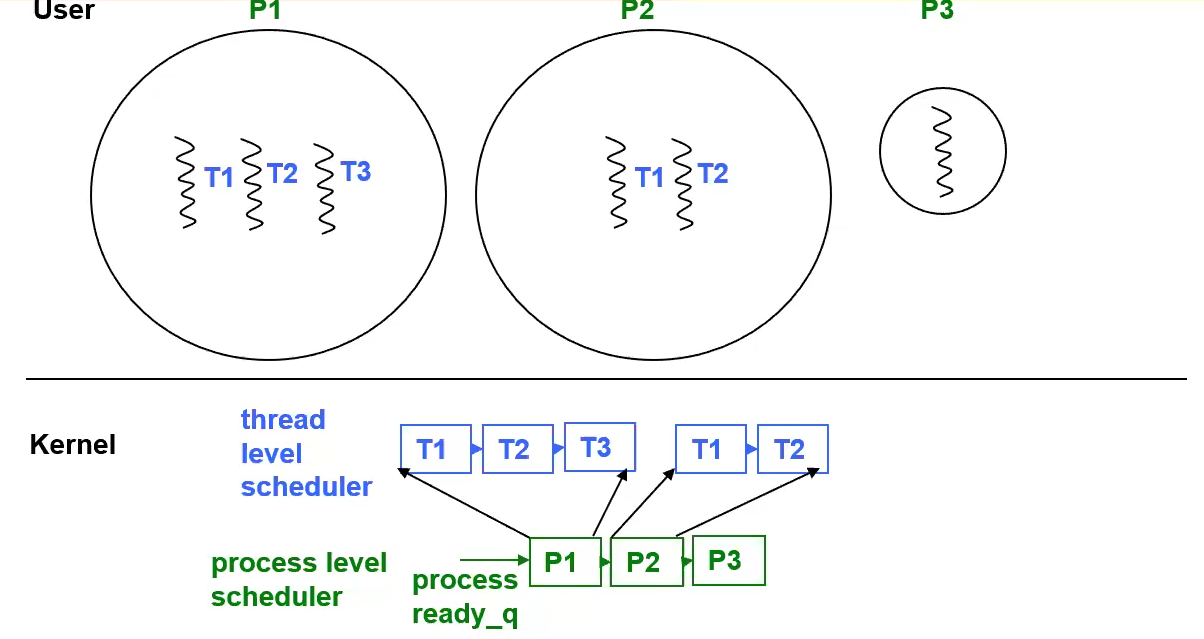 Thread level scheduler, process level scheduler
Thread level scheduler, process level scheduler
- Threading in the application is visible to the OS
- OS provides the thread library
User-Level Threads
This is not the norm.
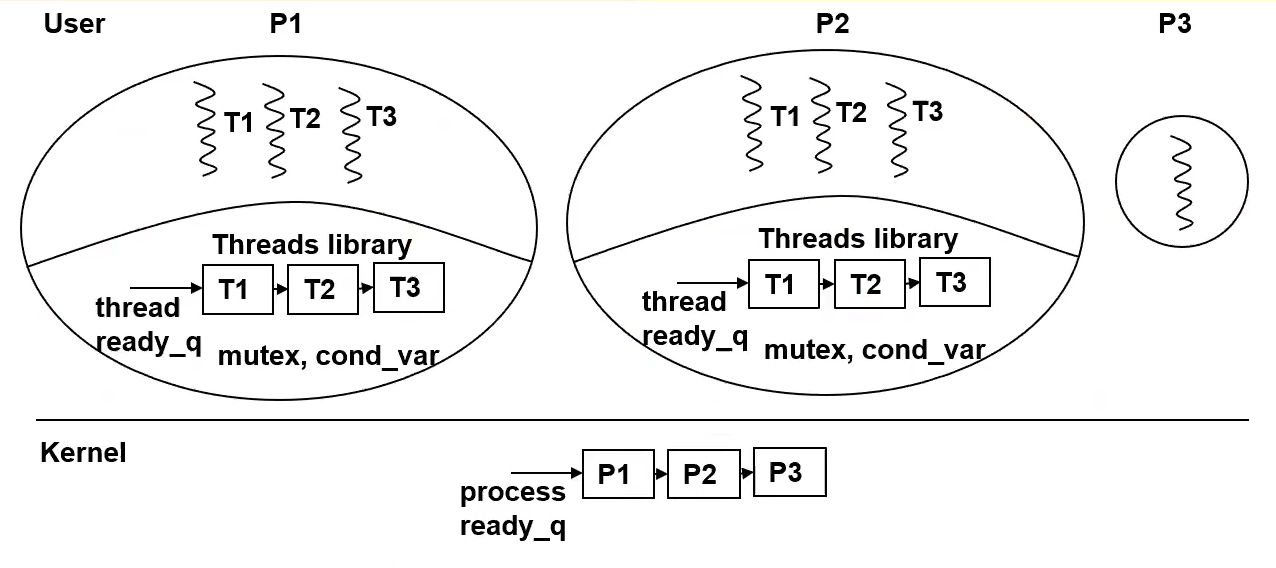
- OS independent
- Scheduler is part of the user space runtime system
- Scheduling is customizable
- Thread switch is cheap (don’t have to do full Context Switch, just save PC, SP, regs)
- Kernel doesn’t know threads exist :(
- Blocking Call by a thread blocks the entire process :(, because we are just simulating threads and don’t actually have true Concurrency capabilities, only fake interleaved pseudo concurrency
- Can be avoided by added a handler for “upcall” that is registered with the OS, giving the thread library an opportunity to schedule some other thread
Symmetric Multiprocessing
Circular transclusion detected: Computer-Science/Symmetric-Multiprocessing