- inodes store metadata for every File on your system
- inodes are fixed size, meaning that their location section is fixed, and therefore they have a max file data size
- inodes are stored as a list of inodes
- They store all the information except the filename and the file data:
- Size in bytes
- Location on disk
- The ordered list of Disk Block Addresses
- Kind of like having one File Allocation Table per file
- Permissions
- User, Group, Other
- Bits go: Read, Write, Execute
- e.g.
-rw-r--r--means user can read and write, and everyone else can read
- User id
- Group id
- Modification date
- Reference Count (How many Hard Links lead to this file?)
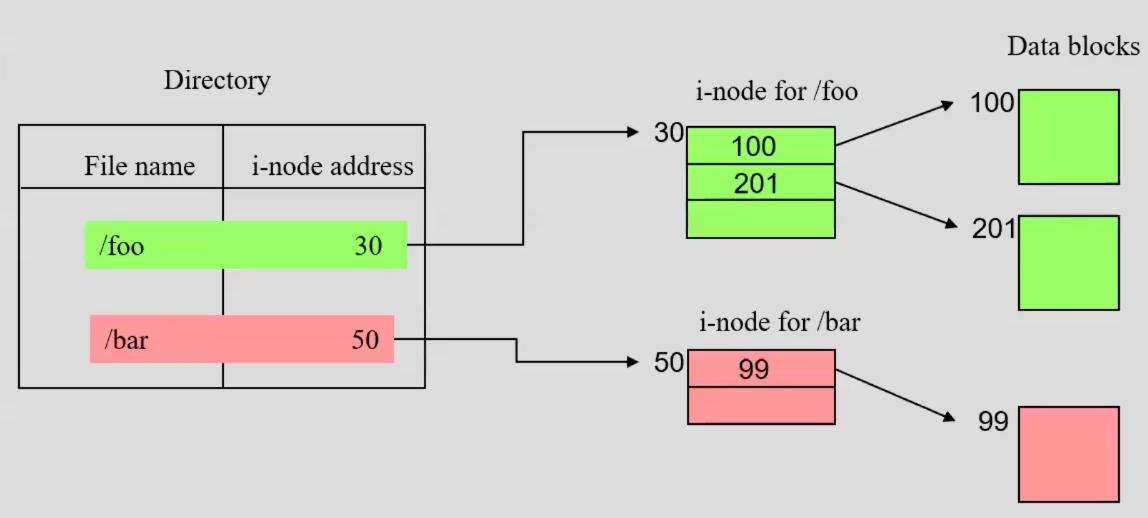
- Every file in a given directory is an entry with the filename and inode number. All other information about the file is retrieved from the inode table by referencing the inode number.
- Inodes numbers are unique at the partition level. Every partition has its own inode table.
- Every used inode has 1 file. Every file has 1 inode.
- List inodes with
ls -i - List inode usage with
df -hi - See
stat <file> - Inode tables can get full before the disk space is actually full
- Inode table size is tied to the disk size, and is created when the Filesystem is created (for EXT)
inumber
inode index number; the index of the inode in the inode Array
Indexed Allocation
This one is basically the UNIX filesystem. The idea is that you store the metadata of the file separately from the data itself. This is implemented using inodes
- Growth: ❌
- You can grow files up to the point that you run out of room for disk block address data in your inode, after which you are maxed out for that inode
- Allocation speed: ✅
- Space: ✅
- No external, minimal internal, similar to linked
- Sequential Access: ✅
- Same as FAT
- Random Access: ☑️
- Same as FAT
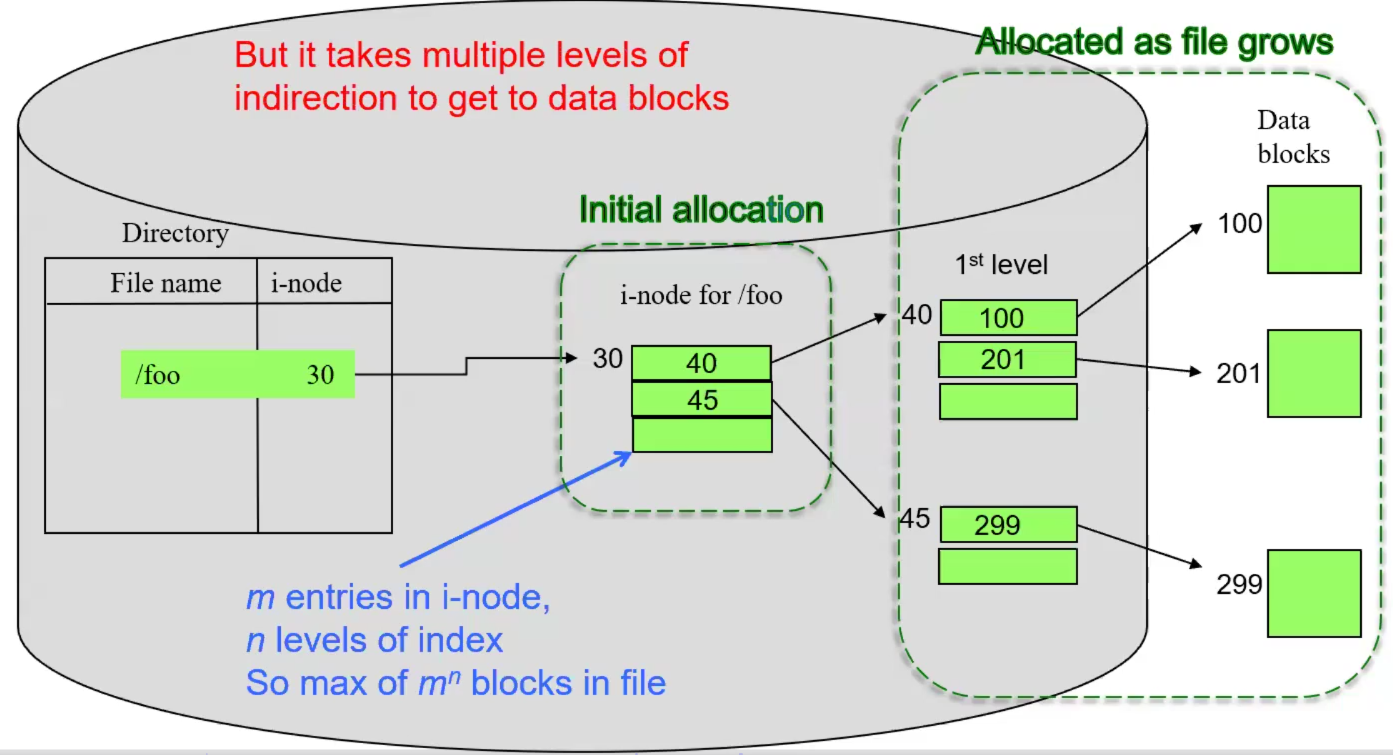
Multilevel Indexed Allocation
The basic idea of inodes, but you have the “Location on disk” part of the inode point to index blocks, instead of logical blocks. Index blocks are just blocks that have logical block entries. They could also have index block entries. You can have as many levels of indirection, such that you have a sufficient ability to grow files. The issue is that there is a lot of overhead going on. By having a system that enables you to have really big files, when you use normal size files, you have a bunch of Internal Fragmentation going on.
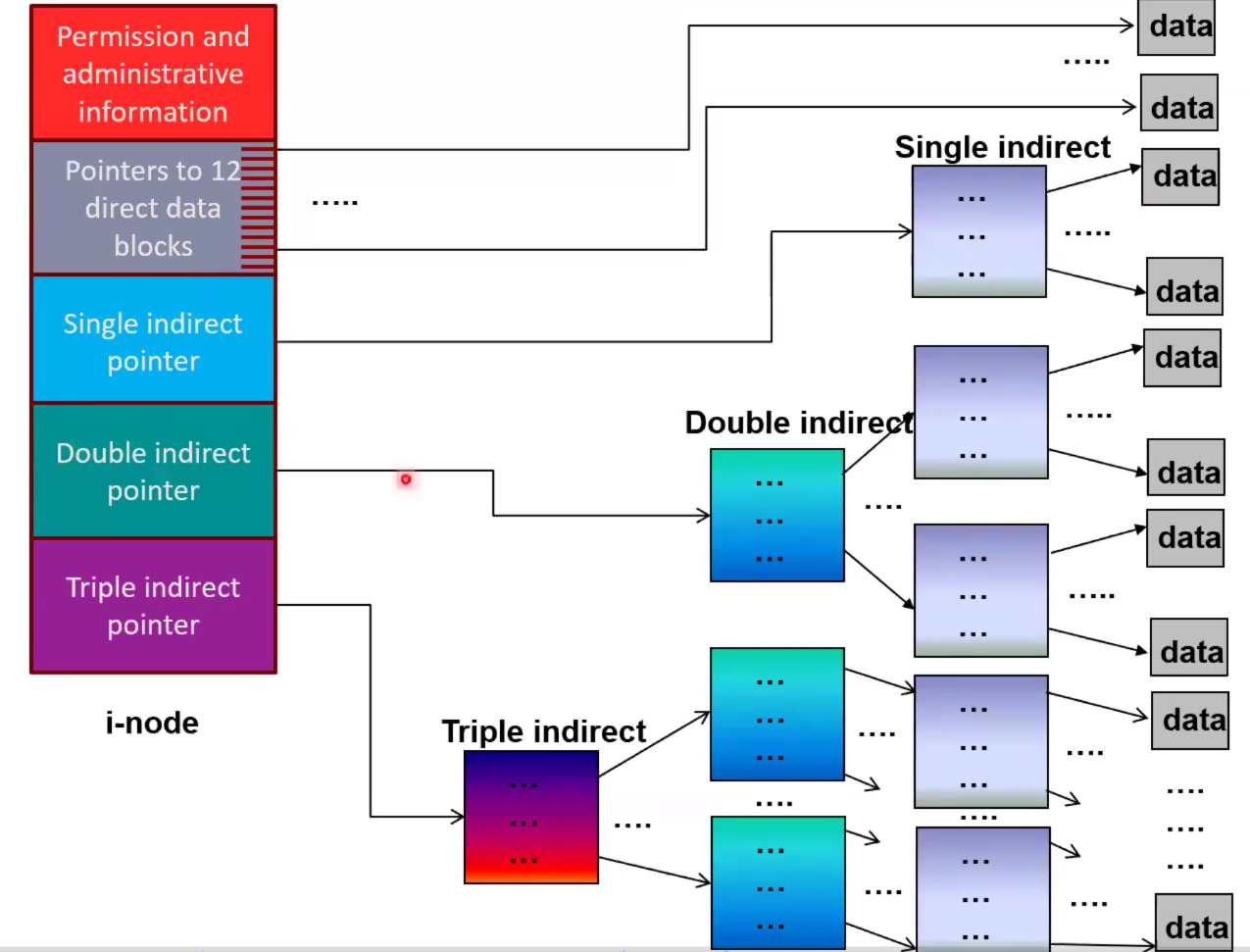
Hybrid Indexed Allocation
Multilevel Indexed Allocation, but there are multiple indirection levels that all coexist. The bigger the file, the bigger the indirection you use. Fill up the pointers least indirection to most indirection, for this reason. The bigger the file, the slower the access.
Link to original
- Growth: ✅
- The multilevel hybrid model fixes the growth issues associated with the basic indexed allocation
- Allocation speed: ✅
- Space: ✅
- No external, minimal internal, similar to linked
- Sequential Access: ✅
- Same as FAT
- Random Access: ☑️
- Same as FAT