A proprietary GPGPU programming platform made by NVIDIA, that provides an interface with the GPU through a superset of C++
The specific features are not defined by an Architecture , but by the specific Hardware . Therefore, CUDA is not hardware-agnostic and must take into account the hardware it is running on.
This is the official reference: https://docs.nvidia.com/cuda/
This is a good reference: https://github.com/Infatoshi/cuda-course/
Typical CUDA Program
CPU allocates CPU memory
CPU copies data to GPU
CPU launches kernel on GPU (processing is done here)
CPU copies results from GPU back to CPU to do something useful with it
Kernel looks like a serial program; says nothing about parallelism. Imagine you are trying to solve a jigsaw puzzle and all you are given is the location of each puzzle piece. The high level algorithm would be designed to take these individual pieces, and solve a single problem for each of them; “put the piece in the correct spot”. As long as all the pieces are assembled in the right place at the end, it works! You don’t need to start at one corner and work your way across the puzzle. You can solve multiple pieces at the same time, as long as they don’t interfere with each other.
Kernel
A GPU Subroutine .
Host
The CPU ; uses RAM on the Motherboard
Device
The GPU ; uses the on-chip VRAM
Conventions
h_A is the host version of the variable A
d_A is the device version of the variable A
Function Execution Space Specifiers
__global__
marks a kernel
runs on GPU
is visible globally (global VRAM )
must return void
uses <<<gridDim, blockDim>>> syntax
__device__
runs on GPU
can be called from other GPU code
__host__
default function on host
usually not explicitly marked
Memory Management
cudaMalloc
cudaMemcpy
copying data
from device to host ⇒ cudaMemcpyDeviceToHost
from host to device ⇒ cudaMemcpyHostToDevice
from device to device ⇒ cudaMemcpyDeviceToDevice
cudaFree
Compiler
For regular C++ we would probably use gcc or clang
For CUDA, we have nvcc
nvcc The Compiler for CUDA
Compiled into PTX assembly
Link to original
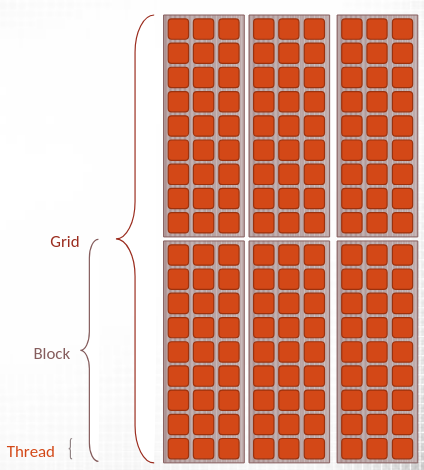
Hierarchy
dim3 gridDim ⇒ number of blocks per griduint3 blockIdx ⇒ index of the block in the griddim3 blockDim ⇒ number of threads per blockuint3 threadIdx ⇒ index of the thread in the block
You can have this hierarchy in 3 dimensions
Thread
A thread is the smallest execution unit
Each thread executes the same kernel code but oeprates on a different part/index of the data
It has its own private local memory (registers)
It has a unique index within its block accessible via threadIdx.<axis>
Warp
Warps are inside of blocks are parllelize 32 threads (or whatever the warp size is).
Instructions are issued to warps that then tell the threads what to do (not directly sent to threads)
The total number of warps in a block is
You can't use 'macro parameter character #' in math mode \left\lceil \frac{T_{B}}{S_{W}} \right\rceil $$where $T_{B}$ is the threads per block, defined below in [[#block|Block]] where $S_{W}$ is the size of a warp, which is usually 32 ## Block A group of threads that can communicate and synchronize with each other. * Threads within the same block can share data quickly using [[#shared-memory|Shared Memory]] and synchronize their execution using `__syncthreads()` * It has a unique index within the grid, accessible via `blockIdx.<axis>` * The dimensions of the block are accessible via `blockDim` * Hard limit for threads per block is 1024 * Optimal block size: $S_{B} = 32 n\ s.t.\ n \in \mathbb{N}^+,\ 32n \leq 1024$ * Optimal limit for threads per block: $T_{B} = \left\lceil \frac{N}{S_{B}} \right\rceil \equiv$ `(N + blockDim- 1) / blockDim` ## Grid The entire set of blocks that execute the kernel * The kernel is launched as a single grid * Blocks in the same grid are independent of each other and cannot communicate directly or synchonize * Blocks can be executed in any order * The dimensions of the grid are accessible via `gridDim` ## Kernel The entire [[Process]] is defined by the kernel, which is the function being executed on the GPU * When you launch a kernel, you specify the configuration of the grid and blocks using the execution configuration syntax: `<<<gridDim, blockDim>>>` ### Kernel Launch Parameters - The execution configuration (of a global function call) is specified by inserting an expression of the form `<<<gridDim, blockDim, Ns, S>>>`, where: - gridDim (dim3) specifies the dimension and size of the grid. - blockDim (dim3) specifies the dimension and size of each block - Ns (size_t) specifies the number of bytes in shared memory that is dynamically allocated per block for this call in addition to the statically allocated memory. (typically omitted) - S (cudaStream_t) specifies the associated stream, is an optional parameter which defaults to 0. `dim3` vs `int` ```c dim3 gridDim(a, b, c); // a blocks in x, b in y, c in z dim3 blockDim(d, e, f); // d threads in x, e in y, f in z ``` ```c int gridDim = abc // abc blocks int blockDim = def // def threads per block ``` * gridDim ⇒ gridDim.x * gridDim.y * gridDim.z = # of blocks being launched * blockDim ⇒ blockDim.x * blockDim.y * blockDim.z = # of threads per block * total threads = (threads per block) * # of blocks = gridDim * blockDim # Memory Tiers ## Global Memory ## Shared Memory ## Local Memory ## Constant Memory ## Texture Memory # Synchronization * `cudaDeviceSynchronize()` ⇒ await all threads to finish, **outside** a kernel * `__syncthreads()` ⇒ await all threads within the same block up, making sure they all get up to this point, inside a kernel * `__syncwarps()` ⇒ await all threads within the same warp to finish a phase of execution, inside a kernel (only neccessary in specific scenarios, where such synchronization isn't already a guarantee) # Diagnostics * [nvidia-smi](https://docs.nvidia.com/deploy/nvidia-smi/index.html) * [nsight](https://developer.nvidia.com/tools-tutorials) * [cuda-gdb](https://docs.nvidia.com/cuda/cuda-gdb/index.html)