Systems of Linear Equations
https://sbarone7.math.gatech.edu/Chapters_1_and_2.pdf
Linear Equation
a’s are coefficients, x’s are variables, n is the dimension (number of variables) e.g. has two dimensions
Row Reduction
Row Operations
- Replacement/Addition
- Interchange
- Scaling Row operations can be used to solve systems of linear equations
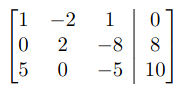 A system of equations written as an augmented matrix
A system of equations written as an augmented matrix
Row operation example (these are augmented)
A linear system is considered consistent if it has solution(s) If two matrices are row equivalent they have the same solution set, meaning that one can be transformed into the other
Row Reduction and Echelon Forms
A rectangular matrix is in echelon form if
- If there are any, all zero rows are at the bottom
- The first non-zero entry (leading entry) of a row is to the right of any leading entries in the row above it
- All elements below a leading entry are zero
 For reduced row echelon form
For reduced row echelon form - All leading entries, if any, are equal to 1.
- Leading entries are the only nonzero entry in their respective column.
Pivots and Free Variables
Pivot position in a matrix A is a location in A that corresponds to a leading 1 in the REF of A Pivot column is the column of the pivot
Free variables are the variables of the non-pivot columns
Any choice of the free variables leads to a solution of the system
^[If you have any free variables you do not have a unique solution]

Theorem for Consistency
A linear system is consistent iff the last column of the augmented matrix does not have a pivot. This is the same as saying that the RREF of the augmented matrix does not have a row of the form
Moreover, if a linear system is consistent, then it has 1. a unique solution iff there are no free variables. 2. infinitely many solutions that are parameterized by free variables
Vector Equations
is all real numbers is dimensions of is rows and columns
Linear Combination
Linear Combination
Let is a linear combination of the vectors, with weights of the ‘s
Link to original
Span
- The set of all linear combinations of the ‘s in called the span of the ‘s
- e.g.
- any 2 vectors in that are not scalar multiplies of each other span Q: Is
Matrix below in form of system of equations where X and Y scale columns 0 and 1, and column 2 are coefficients on the right hand side of the equation. By reducing this matrix to RREF, we can systematically reveal the values of X and Y
Yes.
exists
Homogeneous vs Inhomogeneous
Homogeneous: Homogeneous systems always have a trivial solution, so naturally we would like to know if there are nontrivial, perhaps infinite solutions, namely if there is a free variable and a column with no pivots
Parametric vector forms of solutions to linear systems
You can parameterize the free variables and then write the solution as a vector sum.
The solution is which is Let
Nonhomogenous System
Because right side of augmented is nonzero:
Let
Linear Independence
Given , if the only solution is Linearly Independent
Note: (This might just be wrong) \vec{A} = [\vec{a_0}\ ... \vec{a_n}]\ \big{|}\ \vec{a_i} \in \mathbb{R}^n ^[Same as having n rows of pivots] Linearly Independent
Dependence
- Any of the vectors in the set are a linear combination of the others
- If there is a free variable, so there are infinite solutions to the homogenous equation
- If the columns of A are in , and there are basis vectors in (which is always true), then if the amount of columns in A exceeds the amount of basis vectors that exist in that dimension, it means that there are free variables, which indicates linear dependence
- If one or more of the columns of A is
Geometric interpretation of linearly independent vectors
If two vectors are linearly independent, the are not colinear If 3, then not coplanal If 4, not cospacial
Intro to Linear Transformations
Linear Transformation
Linear transformation
- Domain of T is (where we start)
- Codomain or target of T is
- The vector is the image of under T
- The set of all possible images is called the range
- image range codomain
- When the domain and codomain are both , you can represent them as a Cartesian Graph in , as in a mapping of
- If y is the codomain and x is the domain, the range is the range, the domain is all the images of f(x)
The interpretation of matrix multiplication as a linear transformation
Compute
Calculate so that
Give a Give a that is not in the range of Give a that is not in the span of the columns of (Same question for all)
Range of is a bunch of images of the following form:
For to not be in the range of , it cannot be in the above form, e.g. it can be
Linear
A function is linear if
- T(u + v) = T(u) + T(v)
- T(c) = cT(v)
- “Principle of Superposition”
- If we know , …, then we know every T(v)
- Prove it is linear by proving the addition and multiplication rules
Matrix of Linear Transformations
The standard (basis) vectors
Standard vectors in have a one entry for each dimension, and zeros for the rest, e.g. for :
Standard matrix
Theorem
Let be a linear transformation. Then there is a unique matrix such that In fact, is a and its column is a vector
Two and three dimensional transformations in more detail.
Find standard matrix A for T(x) = 3 for x in
Linear Transformation
A Transformation is a transformation satisfying
1-1
TLDR: 1-1 every column of T is a pivot column
- If there is at most one location in the codomain for every location in the domain
- 1-1 iff standard matrix has pivot in every column
Onto
TLDR: Onto every row of T is a pivot row A linear transformation is onto if there exists a location in the codomain for every location in the domain onto iff the standard matrix has a pivot in every row The matrix A has columns which span . The matrix A has all pivotal rows.
1-1 and Onto
need square matrix if 1-1 then onto if Onto then 1-1
Link to original
Identity and zero matrices
0 Matrix is matrix full of zeroes Identity matrix is a square matrix full of zeroes except for the diagonal, which is all ones. Multiplying with identity matrix always yields the same matrix.
Matrix algebra (sums and products, scalar multiplies, matrix powers)
Sums: same dimensions Matrix multiplication: , , , ,
Transpose of a matrix
Transpose Properties
Invertibility
Definition: is invertible if
A is invertible A is square A is invertible it is row equivalent to the identity
star Linearly dependent Singular
- Mnemonic: After the trial, Johnny Depp was Single Linearly independent Invertible
- This is just the inverse of the above
also
- is invertible
- Basically means that A is 1-1 and Onto, meaning that there is exactly one domain entry for every codomain entry
- (1-1 is at most 1, Onto is at least 1, together they make exactly 1)
- Basically means that A is 1-1 and Onto, meaning that there is exactly one domain entry for every codomain entry
- invertible
Inverse Properties
Inverse Shortcut
Elementary Matrix
An elementary matrix, E, is one that differs by by one row operation.
General way to compute inverse
Row reduce until you get for A
Therefore, if then
Invertible Matrix Theorem - Properties
Let A be an n x n matrix. These statements are all equivalent
a) A is invertible. b) A is row equivalent to I^n. c) A has n pivotal columns. (All columns are pivotal.) d) Ax = 0 has only the trivial solution. e) The columns of A are linearly independent. f) The linear transformation x → Ax is one-to-one. g) The equation Ax = b has a solution for all b in R^n. h) The columns of A span R^n. i) The linear transformation x → Ax is onto. j) There is a n x n matrix C so that CA = I_n. (A has a left inverse.) k) There is a n x n matrix D so that AD = I_n. (A has a right inverse.) l) A^T is invertible.
Abbreviated, invertible matrix theorem (IMT)
B is invertible, A is invertible square A invertible
- 0 not eigenvalue of A
Singular
Noninvertible
Partitioned/Block Matrix
A partitioned matrix is a matrix that you write as a matrix of matrices When doing multiplication with a block matrix, make sure the “receiving” matrix’s entries go first, to respect the lack of commutativity in matrix multiplication. See HW 2.4 if this doesn’t make sense.
Row Column Method
Let A be m x n and B be n x p matrix. Then, the (i, j) entry of AB is row_i A · col_j B. This is the Row Column Method for matrix multiplication
Notable HW Problem
LU Factorization
Triangular Matrices
Upper Triangular: Nonzero along and above Lower Triangular: Nonzero along and below
If A is an m x n matrix that can be row reduced to echelon form without row exchanges, then A = LU . L is a lower triangular m x m matrix with 1’s on the diagonal, U is an echelon form of A.
Suppose A can be row reduced to echelon form U without interchanging rows. Then, To compute the LU decomposition:
- Reduce A to an echelon form U by a sequence of row replacement operations, if possible.
- Place entries in L such that the same sequence of row operations reduces L to I.
Subspaces of
Subset
A subset of , for example, is any collection of vectors that are in
Subspace
A subset H of is a subspace if it is closed within scalar multiplication and vector addition, i.e.
- ,
Columnspace
span of columns of A same as range of A
Nullspace
span of set of that satisfy Null
Basis
Linearly independent vectors that span a subspace
Coordinates, relative to a basis
There are many different possible choice of basis for a subspace. Our choice can give us dramatically different properties.
Standard basis are i, j, k, but you can use other vectors to span the same amount of space if you want.
- What is a determinant? Given a linear transformation T, let us focus on the magnitude of the cross product of the basis vectors. The determinant would be the scalar factor between the original and transformed areas? (Yes)
- If you are calculating some integral over a transformed space, is the jacobian just the determinant of the transformation, or is it related---possibly scaling the result to make sense given standard basis vectors? (Yes)
Dimension
Dimension/Cardinality of a non-zero subspace H, dim H, is the number of vectors in the basis of H. We define dim{0} = 0.
Theorem
Any two choices of , of a non-zero subspace H have the same dimension*
Ex Problems
- dim
- n
- H = has dimension
- n - 1
- use the idea of # 3
- n variables, solve for ito everything else. → one pivot everything else free vars. Therefore n - 1 free vars
- dim(Null A) is the number of
- number of free vars
- dim(Col A) is the number of
- number of pivots
Rank
the rank of a matrix A is the dimension of its column space number of pivots
Nullity
dim(Null A) = Nullity number of of free vars
Notation from class
- Let
- is some basis for the subspace
Rank-Nullity Theorem
If a matrix A has n columns, then
Basis Theorem
Any two bases for a subspace have the same dimension
Invertibility Theorem
Let A be a n x n matrix. These conditions are equivalent.
- A is invertible
- The columns of A are a basis for
- Col A =
- rank A = dim Col A = n
- Null A = {0}
Determinant
Imagine the area of parallelogram created by the basis of a standard vector space, like . Now apply a linear transformation to that vector space. The new area of the new parallelogram has been scaled by a factor of the determinant. is the parallelopiped.
You can also just think of it as the area of the parallelogram spanned by the columns of a matrix R^3 and beyond → parallelopiped and volume (assume n by n matrix because we only know how to find determinants for square matrices)
You can also get the area of S by using the determinant of the matrix created by the vectors that span S, i.e. because you are shifting the standard basis vectors into the vector space dictated by S
Determinant Laws
- det(A) = 0 A is singular
- det(A) 0 A is invertible
- det(Triangular) = product of diagonals
- det A = det
- det(AB) = det A · det B
Determinant Post Row Operations
if A square:
Link to original
- if adding rows to rows on A to get B then
- if swapping rows in A to get B then
- if scaling one row of A by k, then = Exactly the same for columns
Cofactor Expansion
Cofactor expansion is a method used to calculate the Determinant of an matrix . It works by reducing the determinant of the matrix to a sum of determinants of submatrices. It is a recursive definition.
where is the determinant of the submatrix of obtained by deleting the -th row and -th column
The signs for each term of the expansion are determined solely by the position and follow a checkerboard pattern, starting with in the top-left corner
The determinant of a matrix can be calculated by cofactor expansion along any single row or any single column .
Expansion Along Row :
Expansion Along Column :
Strategy: To simplify calculations, it is generally best to choose the row or column with the most zeros.
Link to original
Eigenstuff
Eigenvectors and Eigenvalues
Given
- A is square
- defined, e.g. if then
Eigenvector
is an eigenvector for An eigenvector is a vector solution to the above equation, such that the linear transformation of has the same result as scaling the vector by .
Eigenvalue
is the corresponding eigenvalue () Solve for in , which yields the Characteristic Equation for this system, e.g. in a 2D systems it is . In a 3D+ system, you still have to create the characteristic equation but it requires
Notes:
- point same direction
- point opposite direction
- can be complex even if nothing else in the equation is
- Eigenvalues cannot be determined from the reduced version of a matrix ⭐
- i.e. row reductions change the eigenvalues of a matrix
- The diagonal elements of a triangular matrix are its eigenvalues.
- A invertible iff 0 is not an eigenvalue of A.
- Stochastic matrices have an eigenvalue equal to 1.
- If are eigenvectors that correspond to distinct eigenvalues, then are linearly independent
Defective
An eigenvalue is defective if and only if it does not have a complete Set of Linearly Independent eigenvectors.
Due to ‘s contribution,Neutral Eigenvalue
Eigenspace
- the span of the eigenvectors that correspond to a particular eigenvalue
Link to original
Characteristic Equation
to get values for . Recall means noninvertible. If a matrix isn’t invertible, then we won’t get trivial solutions when solving. Also the idea of reducing the dimension through the transformation is relevant; squishing the basis vectors all onto the same span where the area/volume is 0. Recall eigenvectors remain on the same span despite a linear transformation.
is an eigenvalue of A is singular
trace of a Matrix is the sum of diagonal
Characteristic Polynomial
n degree polynomial → n roots → maximum n eigenvalues (could be repeated)
Algebraic Multiplicity
Algebraic multiplicity of an eigenvalue is how many times an eigenvalue repeatedly occurs as the root of the characteristic polynomial.
Geometric Multiplicity
Link to original
- Geometric multiplicity of an eigenvalue is the number of eigenvectors associated with an eigenvalue; , which is saying how many eigenvector solutions does this eigenvalue have (recall is number of free vars in )

Similar
Link to original
- square matrices A,B are similar we can find P so that
- A,B similar same Characteristic Polynomial same eigenvalues
Markov chains
Stochastic matrix
- Matrix that uses the rates/probabilities
- Columns are probability vectors.
- Sum to 1

Probability Vector
Some vector with nonnegative elements that sum to 1
Stochastic Matrix
A stochastic matrix is a square matrix, P , whose columns are probability vectors. |det(P)| ⇐ 1, only volume contracting or preserving
Markov Chain
A Markov chain is a sequence of probability vectors, and a stochastic matrix P , such that:
Convergence
Regularity
- Stochastic matrix is regular if there strictly has positive entries
- Regular unique steady state vectors
- Irregular steady state vectors
Steady-State Vector
A steady-state vector for P is a vector such that . Fixed point, I/O the same
Ex: Determine the steady state vector for
Goal: solve
Related to eigenvectors. is defined as , also When you reapply a linear transformation approaching infinity times, all the points in the subspace will approach the span of
- If the transformation is regular, a single eigenvector
- For our regular stochastic matrices, this is what the steady state vector is.
- If the transformation is irregular, possibly multiple eigenvectors or none at all. If multiple, points will converge to the closest possible eigenspace.
Theorem
as k →
If is a regular stochastic matrix, then has a unique steady-state vector , and converges to as ; where
M3
Diagonalization
Diagonalizable
Complex Eigenvalues
Complex numbers
Conjugate
- Reflects across the axis Magnitude (or “Modulus”) Polar where is the magnitude
if x and y ,
Euler’s Formula
Suppose has an angle and has The product has angle , and modulus Can use Euler’s formula to make it easier
Complex Eigenvalues
Theorem: Fundamental Theorem of Algebra An degree polynomial has exactly complex roots (including multiplicity).
Theorem
- If is a root of a real polynomial, is also
- Complex roots come in complex conjugate pairs
- If is an eigenvalue of real matrix , with eigenvector , then is an eigenvalue of A with eigenvector
Example
4 of the eigenvalues of a 7 x 7 matrix are -2, 4 + i, -4 - i, and i
- Because there are 3 nonconjugate complex pairs, we know that the remaining eigenvalues are the conjugates of the given complex values
- What is the characteristic polynomial?
Example
The matrix that rotates vectors by radians about the origin and then scales vectors by is:
What are the eigenvalues of ? Find an eigenvector for each eigenvalue
:
:
Could reason the eigenvalue for by the fact that eigenvalues and their eigenvectors come in complex conjugate pairs.
Inner Product, Length, Orthogonality
Dot Product
Length
Orthogonality
- If is a subspace of and , is orthogonal to if it is orthogonal to every vector in
- The set of all vectors orthogonal to a subspace is a itself a subspace, called the Orthogonal Complement of , , W perp
- is orthogonal to each row of
- is orthogonal complement to
- number of columns
Orthogonal Sets
Orthogonal Vector Sets
A set of vectors are an orthogonal set of vectors if every pair in the set is orthogonal to every other vector in the set.
Linear Independence for Orthogonal Sets: If there is an orthogonal set of vectors , then
lin. indep.
Expansion in Orthogonal Basis If is the basis for subspace in and is an orthogonal basis, then for any vector